[TOC]
说明: 原文地址https://blog.csdn.net/bjweimengshu/article/details/80162731
常见几种方式
UUID
虽然可以保证全局唯一,但是占用32位有些太长,而且是无序的,入库时性能较差。
数据库主键
ID的生成对数据库的严重依赖,不但影响性能,而且一旦数据库挂掉,服务将变的不可用。当达到扩展的上线的瓶颈也就是步长的最大值的时候,就不行了。
分布式锁
性能不行。
Redis自增
incr(key)
根据 redis 的官网的 INCR 命令介绍,它是一个原子操作,效果是是将 redis 数据库中 key 的值加一并且返回这个结果。如果 key 不存在,将在执行加一操作前,将这个 key 的值设置为0,也就是说执行这个命令的结果是从 1 开始一直累加下去的。
而且redis为单线程,不存在线程安全问题。每秒可以生成5万个标识。这个可以满足一般的高性能需求了。
SnowFlake算法
snowflake算法所生成的ID结构是什么样子呢?我们来看看下图:
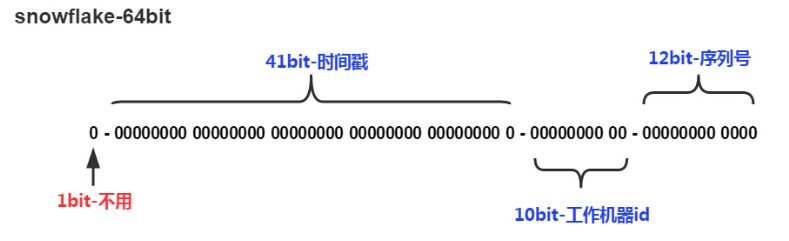
SnowFlake所生成的ID一共分成四部分:
第一位:占用1bit,其值始终是0,没有实际作用。
时间戳:占用41bit,精确到毫秒,总共可以容纳约140年的时间。
工作机器id:占用10bit,其中高位5bit是数据中心ID(datacenterId),低位5bit是工作节点ID(workerId),做多可以容纳1024个节点。
序列号:占用12bit,这个值在同一毫秒同一节点上从0开始不断累加,最多可以累加到4095。
SnowFlake算法在同一毫秒内最多可以生成多少个全局唯一ID呢?只需要做一个简单的乘法:同一毫秒的ID数量 = 1024 X 4096 = 4194304,这个数字在绝大多数并发场景下都是够用的。
SnowFlake的优势和劣势
优点
- 生成ID时不依赖于DB,完全在内存生成,高性能高可用。
- ID呈趋势递增,后续插入索引树的时候性能较好。
- 每个ID中都可以解读出,该ID是在哪个数据中心的哪台工作机器上产生
- 数值型的分布式ID(替换了UUID)
- 高性能的ID生成器(超高400w/s的超高性能)
缺点
- 依赖于系统时钟的一致性。如果某台机器的系统时钟回拨,有可能造成ID冲突,或者ID乱序。
- 他是部分递增的。
- 依赖服务器时间来生成的,所以服务器的时间要是一样的。
实现
https://gitee.com/wayz/snowflake
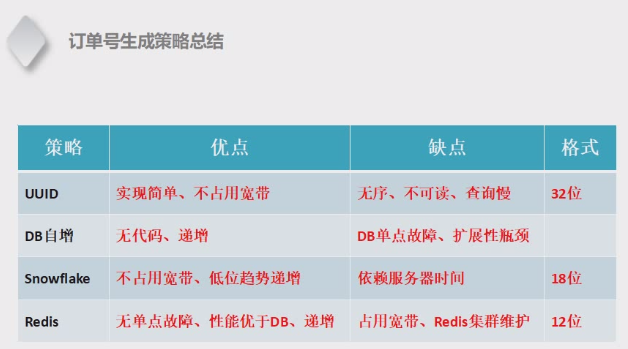
几种方式对比
「真诚赞赏,手留余香」

真诚赞赏,手留余香
使用微信扫描二维码完成支付
