[TOC]
浅析I/O模型
转载地址:https://blog.csdn.net/weixin_34206899/article/details/91771982
转载地址:https://www.zhihu.com/question/29005375/answer/667616386
什么是阻塞?什么是非阻塞?
阻塞就是:当某个事件或者任务在执行过程中,它发出一个请求操作,但是由于该请求操作需要的条件不满足,那么就会一直在那等待,直至条件满足;
非阻塞就是:当某个事件或者任务在执行过程中,它发出一个请求操作,如果该请求操作需要的条件不满足,会立即返回一个标志信息告知条件不满足,不会一直在那等待。
这就是阻塞和非阻塞的区别。也就是说阻塞和非阻塞的区别关键在于 当发出请求一个操作时,如果条件不满足,是会一直等待还是返回一个标志信息。
阻塞和非阻塞指的是执行一个操作是等操作结束再返回,还是马上返回。
比如餐馆的服务员为用户点菜,当有用户点完菜后,服务员将菜单给后台厨师,此时有两种方式:
· 第一种:就在出菜窗口等待,直到厨师炒完菜后将菜送到窗口,然后服务员再将菜送到用户手中;
· 第二种:等一会再到窗口来问厨师,某个菜好了没?如果没有先处理其他事情,等会再去问一次;
第一种就是阻塞方式,第二种则是非阻塞的。
同步和异步又是另外一个概念,它是事件本身的一个属性。还拿前面点菜为例,服务员直接跟厨师打交道,菜出来没出来,服务员直接指导,但只有当厨师将菜送到服务员手上,这个过程才算正常完成,这就是同步的事件。同样是点菜,有些餐馆有专门的传菜人员,当厨师炒好菜后,传菜员将菜送到传菜窗口,并通知服务员,这就变成异步的了。其实异步还可以分为两种:带通知的和不带通知的。前面说的那种属于带通知的。有些传菜员干活可能主动性不是很够,不会主动通知你,你就需要时不时的去关注一下状态。这种就是不带通知的异步。
对于同步的事件,你只能以阻塞的方式去做。而对于异步的事件,阻塞和非阻塞都是可以的。非阻塞又有两种方式:主动查询和被动接收消息。被动不意味着一定不好,在这里它恰恰是效率更高的,因为在主动查询里绝大部分的查询是在做无用功。对于带通知的异步事件,两者皆可。而对于不带通知的,则只能用主动查询。
但是对于非阻塞和异步的概念有点混淆,非阻塞只是意味着方法调用不阻塞,就是说作为服务员的你不用一直在窗口等,非阻塞的逻辑是"等可以读(写)了告诉你",但是完成读(写)工作的还是调用者(线程)服务员的你等菜到窗口了还是要你亲自去拿。而异步意味这你可以不用亲自去做读(写)这件事,你的工作让别人(别的线程)来做,你只需要发起调用,别人把工作做完以后,或许再通知你,它的逻辑是“我做完了 告诉/不告诉 你”,他和非阻塞的区别在于一个是"已经做完"另一个是"可以去做"。
什么是阻塞IO?什么是非阻塞IO?
在了解阻塞IO和非阻塞IO之前,先看下一个具体的IO操作过程是怎么进行的。
通常来说,IO操作包括:对硬盘的读写、对socket的读写以及外设的读写。
当用户线程发起一个IO请求操作(本文以读请求操作为例),内核会去查看要读取的数据是否就绪,对于阻塞IO来说,如果数据没有就绪,则会一直在那等待,直到数据就绪;对于非阻塞IO来说,如果数据没有就绪,则会返回一个标志信息告知用户线程当前要读的数据没有就绪。当数据就绪之后,便将数据拷贝到用户线程,这样才完成了一个完整的IO读请求操作,也就是说一个完整的IO读请求操作包括两个阶段:
1)查看数据是否就绪;
2)进行数据拷贝(内核将数据拷贝到用户线程)。
那么阻塞(blocking IO)和非阻塞(non-blocking IO)的区别就在于第一个阶段,如果数据没有就绪,在查看数据是否就绪的过程中是一直等待,还是直接返回一个标志信息。
Java中传统的IO都是阻塞IO,比如通过socket来读数据,调用read()方法之后,如果数据没有就绪,当前线程就会一直阻塞在read方法调用那里,直到有数据才返回;而如果是非阻塞IO的话,当数据没有就绪,read()方法应该返回一个标志信息,告知当前线程数据没有就绪,而不是一直在那里等待。
什么是同步IO?什么是异步IO?
同步IO即 如果一个线程请求进行IO操作,在IO操作完成之前,该线程会被阻塞;而异步IO为 如果一个线程请求进行IO操作,IO操作不会导致请求线程被阻塞。
事实上,同步IO和异步IO模型是针对用户线程和内核的交互来说的:
对于同步IO:当用户发出IO请求操作之后,如果数据没有就绪,需要通过用户线程或者内核不断地去轮询数据是否就绪,当数据就绪时,再将数据从内核拷贝到用户线程;
而异步IO:只有IO请求操作的发出是由用户线程来进行的,IO操作的两个阶段都是由内核自动完成,然后发送通知告知用户线程IO操作已经完成。也就是说在异步IO中,不会对用户线程产生任何阻塞。
这是同步IO和异步IO关键区别所在,同步IO和异步IO的关键区别反映在数据拷贝阶段是由用户线程完成还是内核完成。所以说异步IO必须要有操作系统的底层支持。
注意
注意同步IO和异步IO与阻塞IO和非阻塞IO是不同的两组概念。
阻塞IO和非阻塞IO是反映在当用户请求IO操作时,如果数据没有就绪,是用户线程一直等待数据就绪,还是会收到一个标志信息这一点上面的。也就是说,阻塞IO和非阻塞IO是反映在IO操作的第一个阶段,在查看数据是否就绪时是如何处理的。
五种IO模型
概述
分别是:阻塞IO、非阻塞IO、多路复用IO、信号驱动IO以及异步IO。
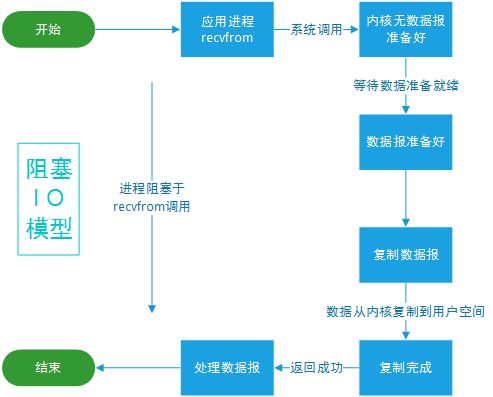
1. 阻塞IO模型(BIO)
最传统的一种IO模型,即在读写数据过程中会发生阻塞现象。
当用户线程发出IO请求之后,内核会去查看数据是否就绪,如果没有就绪就会等待数据就绪,而用户线程就会处于阻塞状态,用户线程交出CPU。当数据就绪之后,内核会将数据拷贝到用户线程,并返回结果给用户线程,用户线程才解除block状态。
典型的阻塞IO模型的例子为:
data = socket.read();
如果数据没有就绪,就会一直阻塞在read方法。
流程图
模拟场景
Java3y跟女朋友去买喜茶,排了很久的队终于可以点饮料了。我要绿研,谢谢。可是喜茶不是点了单就能立即拿,于是我在喜茶门口等了一小时才拿到绿研。
在门口干等一小时
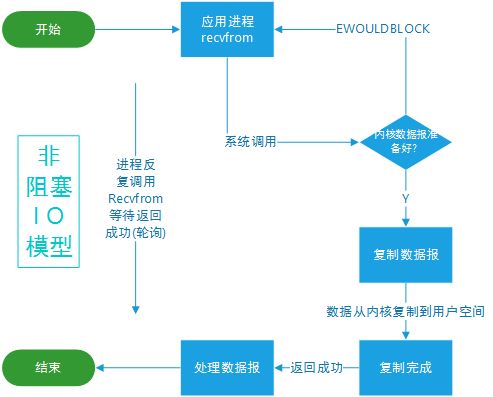
2. 非阻塞IO模型
当用户线程发起一个read操作后,并不需要等待,而是马上就得到了一个结果。如果结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦内核中的数据准备好了,并且又再次收到了用户线程的请求,那么它马上就将数据拷贝到了用户线程,然后返回。
所以事实上,在非阻塞IO模型中,用户线程需要不断地询问内核数据是否就绪,也就说非阻塞IO不会交出CPU,而会一直占用CPU。
典型的非阻塞IO模型一般如下:
while(true){
data = socket.read();
if(data!= error){
处理数据
break;
}
}
但是对于非阻塞IO就有一个非常严重的问题,在while循环中需要不断地去询问内核数据是否就绪,这样会导致CPU占用率非常高,因此一般情况下很少使用while循环这种方式来读取数据。
流程图
模拟场景
Java3y跟女朋友去买一点点,排了很久的队终于可以点饮料了。我要波霸奶茶,谢谢。可是一点点不是点了单就能立即拿,同时服务员告诉我:你大概要等半小时哦。你们先去逛逛吧~于是Java3y跟女朋友去玩了几把斗地主,感觉时间差不多了。于是又去一点点问:请问到我了吗?我的单号是xxx。服务员告诉Java3y:还没到呢,现在的单号是XXX,你还要等一会,可以去附近耍耍。问了好几次后,终于拿到我的波霸奶茶了。
去逛了下街、斗了下地主,时不时问问到我了没有
3. 多路复用IO模型(Reactor模式)
多路复用IO模型是目前使用得比较多的模型。Java NIO实际上就是多路复用IO。
在多路复用IO模型中,会有一个线程不断去轮询多个socket的状态,只有当socket真正有读写事件时,才真正调用实际的IO读写操作。因为在多路复用IO模型中,只需要使用一个线程就可以管理多个socket,系统不需要建立新的进程或者线程,也不必维护这些线程和进程,并且只有在真正有socket读写事件进行时,才会使用IO资源,所以它大大减少了资源占用。
在Java NIO中,是通过selector.select()去查询每个通道是否有到达事件,如果没有事件,则一直阻塞在那里,因此这种方式会导致用户线程的阻塞。
也许有朋友会说,我可以采用 多线程+ 阻塞IO 达到类似的效果,但是由于在多线程 + 阻塞IO 中,每个socket对应一个线程,这样会造成很大的资源占用,并且尤其是对于长连接来说,线程的资源一直不会释放,如果后面陆续有很多连接的话,就会造成性能上的瓶颈。
而多路复用IO模式,通过一个线程就可以管理多个socket,只有当socket真正有读写事件发生才会占用资源来进行实际的读写操作。因此,多路复用IO比较适合连接数比较多的情况。
另外多路复用IO为何比非阻塞IO模型的效率高是因为在非阻塞IO中,不断地询问socket状态时通过用户线程去进行的,而在多路复用IO中,轮询每个socket状态是内核在进行的,这个效率要比用户线程要高的多。
不过要注意的是,多路复用IO模型是通过轮询的方式来检测是否有事件到达,并且对到达的事件逐一进行响应。因此对于多路复用IO模型来说,一旦事件响应体很大,那么就会导致后续的事件迟迟得不到处理,并且会影响新的事件轮询。
流程图
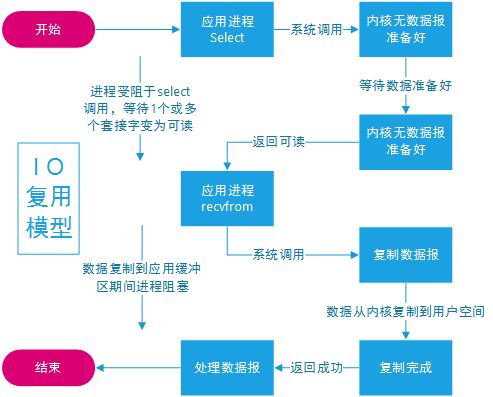
1)当用户进程调用了select,那么整个进程会被block;
2)而同时,kernel会“监视”所有select负责的socket;
3)当任何一个socket中的数据准备好了,select就会返回;
4)这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程(空间)。
所以,I/O 多路复用的特点是通过一种机制一个进程能同时等待多个文件描述符,而这些文件描述符其中的任意一个进入读就绪状态,select()函数就可以返回。
select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。
模拟场景
Java3y跟女朋友去麦当劳吃汉堡包,现在就厉害了可以使用微信小程序点餐了。于是跟女朋友找了个地方坐下就用小程序点餐了。点餐了之后玩玩斗地主、聊聊天什么的。时不时听到广播在复述XXX请取餐,反正我的单号还没到,就继续玩呗。~~等听到广播的时候再取餐就是了。时间过得挺快的,此时传来:Java3y请过来取餐。于是我就能拿到我的麦辣鸡翅汉堡了。
听广播取餐,广播不是为我一个人服务。广播喊到我了,我过去取就Ok了。
4. 信号驱动IO模型
在信号驱动IO模型中,当用户线程发起一个IO请求操作,会给对应的socket注册一个信号函数,然后用户线程会继续执行,当内核数据就绪时会发送一个信号给用户线程,用户线程接收到信号之后,便在信号函数中调用IO读写操作来进行实际的IO请求操作。
5. 异步IO模型
异步IO模型才是最理想的IO模型,在异步IO模型中,当用户线程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从内核的角度,当它受到一个asynchronous read之后,它会立刻返回,说明read请求已经成功发起了,因此不会对用户线程产生任何block。然后,内核会等待数据准备完成,然后将数据拷贝到用户线程,当这一切都完成之后,内核会给用户线程发送一个信号,告诉它read操作完成了。也就说用户线程完全不需要实际的整个IO操作是如何进行的,只需要先发起一个请求,当接收内核返回的成功信号时表示IO操作已经完成,可以直接去使用数据了。
也就说在异步IO模型中,IO操作的两个阶段都不会阻塞用户线程,这两个阶段都是由内核自动完成,然后发送一个信号告知用户线程操作已完成。用户线程中不需要再次调用IO函数进行具体的读写。这点是和信号驱动模型有所不同的,在信号驱动模型中,当用户线程接收到信号表示数据已经就绪,然后需要用户线程调用IO函数进行实际的读写操作;而在异步IO模型中,收到信号表示IO操作已经完成,不需要再在用户线程中调用iO函数进行实际的读写操作。
总结
注意,异步IO是需要操作系统的底层支持,在Java 7中,提供了Asynchronous IO。 前面四种IO模型实际上都属于同步IO,只有最后一种是真正的异步IO,因为无论是多路复用IO还是信号驱动模型,IO操作的第2个阶段都会引起用户线程阻塞,也就是内核进行数据拷贝的过程都会让用户线程阻塞。
两种高性能IO设计模式
在传统的网络服务设计模式中,有两种比较经典的模式:
一种是多线程,一种是线程池。
对于多线程模式,也就说来了client,服务器就会新建一个线程来处理该client的读写事件,如下图所示:
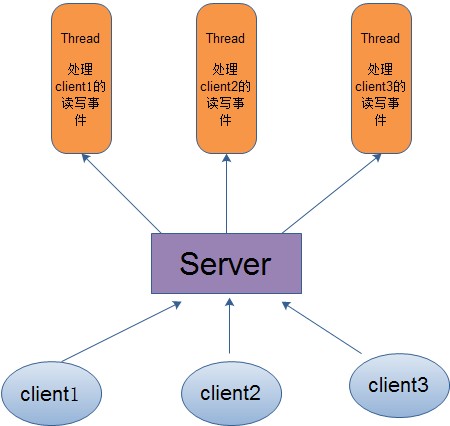
这种模式虽然处理起来简单方便,但是由于服务器为每个client的连接都采用一个线程去处理,使得资源占用非常大。因此,当连接数量达到上限时,再有用户请求连接,直接会导致资源瓶颈,严重的可能会直接导致服务器崩溃。
因此,为了解决这种一个线程对应一个客户端模式带来的问题,提出了采用线程池的方式,也就说创建一个固定大小的线程池,来一个客户端,就从线程池取一个空闲线程来处理,当客户端处理完读写操作之后,就交出对线程的占用。因此这样就避免为每一个客户端都要创建线程带来的资源浪费,使得线程可以重用。
但是线程池也有它的弊端,如果连接大多是长连接,因此可能会导致在一段时间内,线程池中的线程都被占用,那么当再有用户请求连接时,由于没有可用的空闲线程来处理,就会导致客户端连接失败,从而影响用户体验。因此,线程池比较适合大量的短连接应用。
因此便出现了下面的两种高性能IO设计模式:Reactor和Proactor。
在Reactor模式中,会先对每个client注册感兴趣的事件,然后有一个线程专门去轮询每个client是否有事件发生,当有事件发生时,便顺序处理每个事件,当所有事件处理完之后,便再转去继续轮询,如下图所示:
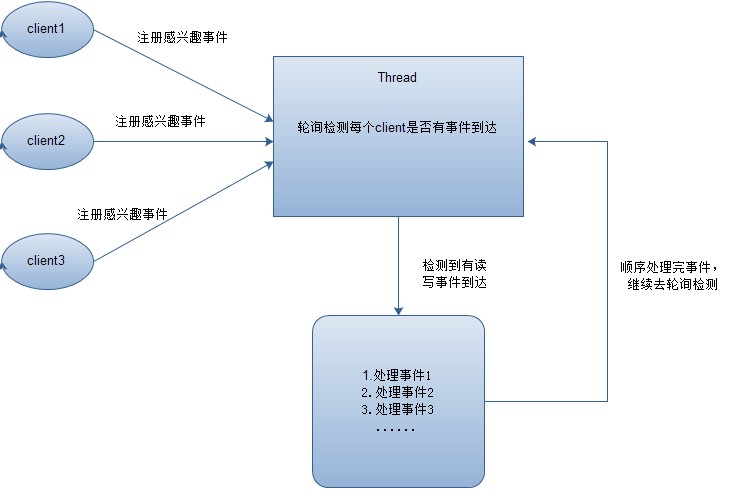
从这里可以看出,上面的五种IO模型中的多路复用IO就是采用Reactor模式。注意,上面的图中展示的 是顺序处理每个事件,当然为了提高事件处理速度,可以通过多线程或者线程池的方式来处理事件。
在Proactor模式中,当检测到有事件发生时,会新起一个异步操作,然后交由内核线程去处理,当内核线程完成IO操作之后,发送一个通知告知操作已完成,可以得知,异步IO模型采用的就是Proactor模式。
模型对比

「真诚赞赏,手留余香」

真诚赞赏,手留余香
使用微信扫描二维码完成支付
