[TOC]
转载地址:https://www.zhihu.com/question/29005375
转载地址:https://yq.aliyun.com/articles/2371
转载地址:https://segmentfault.com/a/1190000017040893
转载地址:https://www.cnblogs.com/pony1223/p/8138233.html
传统IO
我们知道,一个新技术的出现总是伴随着改进和提升,Java NIO的出现亦如此。
传统 I/O 是阻塞式I/O,主要问题是系统资源的浪费。比如我们为了读取一个TCP连接的数据,调用 InputStream 的 read() 方法,这会使当前线程被挂起,直到有数据到达才被唤醒,那该线程在数据到达这段时间内,占用着内存资源(存储线程栈)却无所作为,也就是俗话说的占着茅坑不拉屎,为了读取其他连接的数据,我们不得不启动另外的线程。在并发连接数量不多的时候,这可能没什么问题,然而当连接数量达到一定规模,内存资源会被大量线程消耗殆尽。另一方面,线程切换需要更改处理器的状态,比如程序计数器、寄存器的值,因此非常频繁的在大量线程之间切换,同样是一种资源浪费。
随着技术的发展,现代操作系统提供了新的I/O机制,可以避免这种资源浪费。基于此,诞生了Java NIO,NIO的代表性特征就是非阻塞I/O。紧接着我们发现,简单的使用非阻塞I/O并不能解决问题,因为在非阻塞模式下,read()方法在没有读取到数据时就会立即返回,不知道数据何时到达的我们,只能不停的调用read()方法进行重试,这显然太浪费CPU资源了,从下文可以知道,Selector组件正是为解决此问题而生。
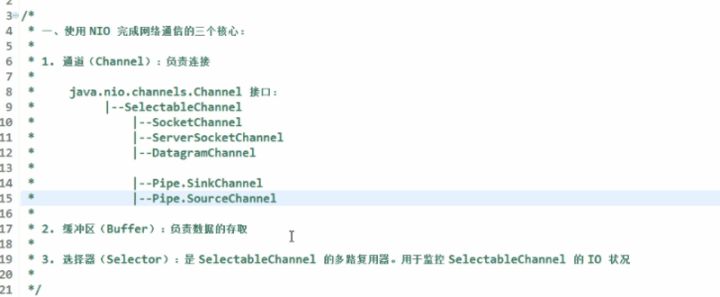
概述
NIO被叫为 no-blocking io,其实是在网络这个层次中理解的,对于FileChannel来说一样是阻塞。
所以说:我们通常使用NIO是在网络中使用的,网上大部分讨论NIO都是在网络通信的基础之上的!说NIO是非阻塞的NIO也是网络中体现的!
常用流程
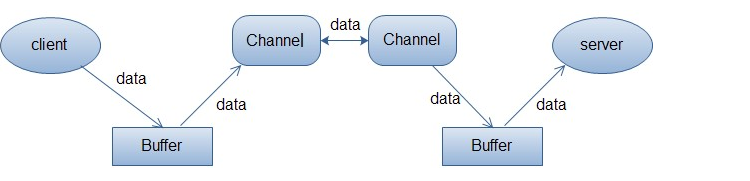
形象比喻NIO模式
转载地址:https://www.cnblogs.com/pony1223/p/8138233.html
传统的socket IO中,需要为每个连接创建一个线程,当并发的连接数量非常巨大时,线程所占用的栈内存和CPU线程切换的开销将非常巨大。使用NIO,不再需要为每个线程创建单独的线程,可以用一个含有限数量线程的线程池,甚至一个线程来为任意数量的连接服务。由于线程数量小于连接数量,所以每个线程进行IO操作时就不能阻塞,如果阻塞的话,有些连接就得不到处理,NIO提供了这种非阻塞的能力。
小量的线程如何同时为大量连接服务呢,答案就是就绪选择。这就好比到餐厅吃饭,每来一桌客人,都有一个服务员专门为你服务,从你到餐厅到结帐走人,这样方式的好处是服务质量好,一对一的服务,VIP啊,可是缺点也很明显,成本高,如果餐厅生意好,同时来100桌客人,就需要100个服务员,那老板发工资的时候得心痛死了,这就是传统的一个连接一个线程的方式。
老板是什么人啊,精着呢。这老板就得捉摸怎么能用10个服务员同时为100桌客人服务呢,老板就发现,服务员在为客人服务的过程中并不是一直都忙着,客人点完菜,上完菜,吃着的这段时间,服务员就闲下来了,可是这个服务员还是被这桌客人占用着,不能为别的客人服务,用华为领导的话说,就是工作不饱满。那怎么把这段闲着的时间利用起来呢。这餐厅老板就想了一个办法,让一个服务员(前台)专门负责收集客人的需求,登记下来,比如有客人进来了、客人点菜了,客人要结帐了,都先记录下来按顺序排好。每个服务员到这里领一个需求,比如点菜,就拿着菜单帮客人点菜去了。点好菜以后,服务员马上回来,领取下一个需求,继续为别人客人服务去了。这种方式服务质量就不如一对一的服务了,当客人数据很多的时候可能需要等待。但好处也很明显,由于在客人正吃饭着的时候服务员不用闲着了,服务员这个时间内可以为其他客人服务了,原来10个服务员最多同时为10桌客人服务,现在可能为50桌,60客人服务了。
这种服务方式跟传统的区别有两个:
1、增加了一个角色,要有一个专门负责收集客人需求的人。NIO里对应的就是Selector。
2、由阻塞服务方式改为非阻塞服务了,客人吃着的时候服务员不用一直侯在客人旁边了。传统的IO操作,比如read(),当没有数据可读的时候,线程一直阻塞被占用,直到数据到来。NIO中没有数据可读时,read()会立即返回0,线程不会阻塞。
NIO中,客户端创建一个连接后,先要将连接注册到Selector,相当于客人进入餐厅后,告诉前台你要用餐,前台会告诉你你的桌号是几号,然后你就可能到那张桌子坐下了,SelectionKey就是桌号。当某一桌需要服务时,前台就记录哪一桌需要什么服务,比如1号桌要点菜,2号桌要结帐,服务员从前台取一条记录,根据记录提供服务,完了再来取下一条。这样服务的时间就被最有效的利用起来了。

为什么用
传统流I/O是基于字节的,所有I/O都被视为单个字节的移动;而NIO是基于块的,大家可能猜到了,NIO的性能肯定优于流I/O。没错!其性能的提高 要得益于其使用的结构更接近操作系统执行I/O的方式:通道和缓冲器。我们可以把它想象成一个煤矿,通道是一个包含煤层(数据)的矿藏,而缓冲器则是派送 到矿藏的卡车。卡车载满煤炭而归,我们再从卡车上获得煤炭。也就是说,我们并没有直接和通道交互;我们只是和缓冲器交互,并把缓冲器派送到通道。通道要么 从缓冲器获得数据,要么向缓冲器发送数据。(这段比喻出自Java编程思想)
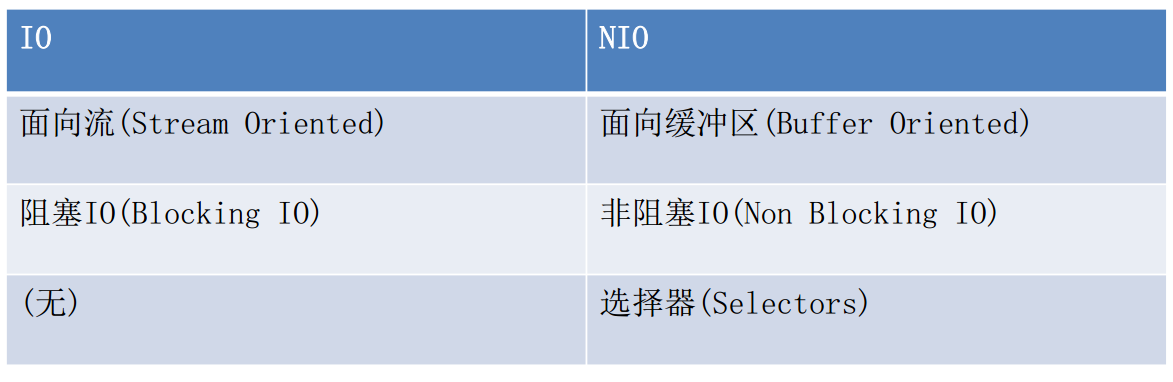
可简单认为:IO是面向流的处理,NIO是面向块(缓冲区)的处理
NIO的主要应用在高性能、高容量服务端应用程序,典型的有Apache Mina就是基于它的。
多路复用模型
我们在网络中使用NIO往往是I/O模型的多路复用模型!
模拟场景
Java3y跟女朋友去麦当劳吃汉堡包,现在就厉害了可以使用微信小程序点餐了。于是跟女朋友找了个地方坐下就用小程序点餐了。点餐了之后玩玩斗地主、聊聊天什么的。时不时听到广播在复述XXX请取餐,反正我的单号还没到,就继续玩呗。~~等听到广播的时候再取餐就是了。时间过得挺快的,此时传来:Java3y请过来取餐。于是我就能拿到我的麦辣鸡翅汉堡了。
听广播取餐,广播不是为我一个人服务。广播喊到我了,我过去取就Ok了。
三个核心部分组成
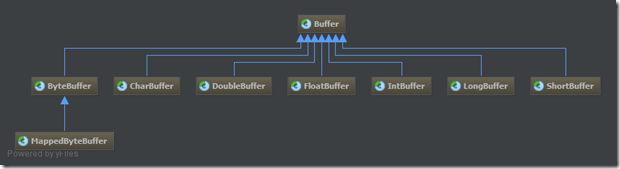
Buffer缓冲区

缓冲区实质上就是一个数组,但它不仅仅是一个数组,缓冲区还提供了对数据的结构化访问,而且还可以跟踪系统的读/写进程。
讲缓冲区细节之前,我们先来看一下缓冲区“家谱”:
buffer缓冲区和Channel管道
在NIO中并不是以流的方式来处理数据的,而是以buffer缓冲区和Channel管道配合使用来处理数据。
简单理解一下:
- Channel管道比作成铁路,buffer缓冲区比作成火车(运载着货物)
而我们的NIO就是通过Channel管道运输着存储数据的Buffer缓冲区的来实现数据的处理!
-
要时刻记住:Channel不与数据打交道,它只负责运输数据。与数据打交道的是Buffer缓冲区
-
- Channel–>运输
- Buffer–>数据
相对于传统IO而言,流是单向的。对于NIO而言,有了Channel管道这个概念,我们的读写都是双向的(铁路上的火车能从广州去北京、自然就能从北京返还到广州)!
buffer缓冲区核心要点
我们来看看Buffer缓冲区有什么值得我们注意的地方。
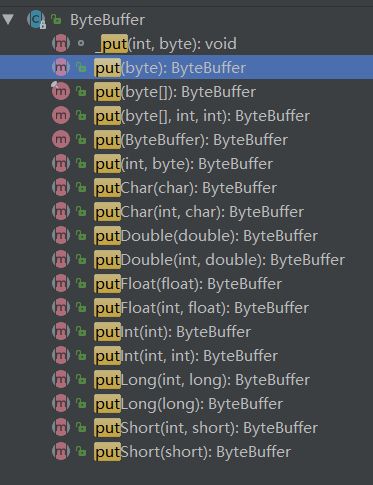
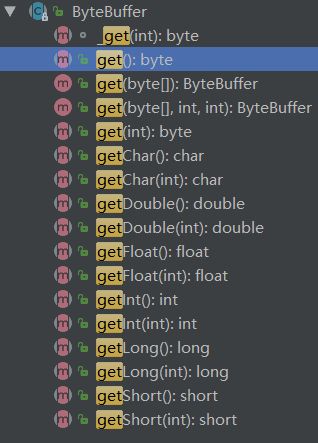
Buffer是缓冲区的抽象类, 其中ByteBuffer是用得最多的实现类(在管道中读写字节数据)。

拿到一个缓冲区我们往往会做什么?很简单,就是读取缓冲区的数据/写数据到缓冲区中。所以,缓冲区的核心方法就是:
put()get()
Buffer类维护了4个核心变量属性来提供关于其所包含的数组的信息。它们是:
public abstract class Buffer {
/**
* The characteristics of Spliterators that traverse and split elements
* maintained in Buffers.
*/
static final int SPLITERATOR_CHARACTERISTICS =
Spliterator.SIZED | Spliterator.SUBSIZED | Spliterator.ORDERED;
// Invariants: mark <= position <= limit <= capacity
private int mark = -1;
private int position = 0;
private int limit;
private int capacity;
4个核心变量
1. 容量Capacity
缓冲区能够容纳的数据元素的最大数量。容量在缓冲区创建时被设定,并且永远不能被改变。(不能被改变的原因也很简单,底层是数组嘛)
2. 上界Limit
缓冲区里的数据的总数,代表了当前缓冲区中一共有多少数据
3. 位置Position
下一个要被读或写的元素的位置。Position会自动由相应的 get( )和 put( )函数更新。
4. 标记Mark
一个备忘位置。用于记录上一次读写的位置

buffer核心变量值的变化
public class App {
public static void main(String[] args) {
// 创建一个缓冲区
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
// 看一下初始时4个核心变量的值
System.out.println("初始时-->limit--->" + byteBuffer.limit());
System.out.println("初始时-->position--->" + byteBuffer.position());
System.out.println("初始时-->capacity--->" + byteBuffer.capacity());
System.out.println("初始时-->mark--->" + byteBuffer.mark());
System.out.println("--------------------------------------");
// 添加一些数据到缓冲区中
String s = "Java3y";
byteBuffer.put(s.getBytes());
// 看一下初始时4个核心变量的值
System.out.println("put完之后-->limit--->" + byteBuffer.limit());
System.out.println("put完之后-->position--->" + byteBuffer.position());
System.out.println("put完之后-->capacity--->" + byteBuffer.capacity());
System.out.println("put完之后-->mark--->" + byteBuffer.mark());
System.out.println("--------------------------------------");
byteBuffer.flip();
// 看一下初始时4个核心变量的值
System.out.println("flip完之后-->limit--->" + byteBuffer.limit());
System.out.println("flip完之后-->position--->" + byteBuffer.position());
System.out.println("flip完之后-->capacity--->" + byteBuffer.capacity());
System.out.println("flip完之后-->mark--->" + byteBuffer.mark());
}
}
运行结果
初始时-->limit--->1024
初始时-->position--->0
初始时-->capacity--->1024
初始时-->mark--->java.nio.HeapByteBuffer[pos=0 lim=1024 cap=1024]
--------------------------------------
put完之后-->limit--->1024
put完之后-->position--->6
put完之后-->capacity--->1024
put完之后-->mark--->java.nio.HeapByteBuffer[pos=6 lim=1024 cap=1024]
--------------------------------------
flip完之后-->limit--->6
flip完之后-->position--->0
flip完之后-->capacity--->1024
flip完之后-->mark--->java.nio.HeapByteBuffer[pos=0 lim=6 cap=1024]
缓存区拿数据
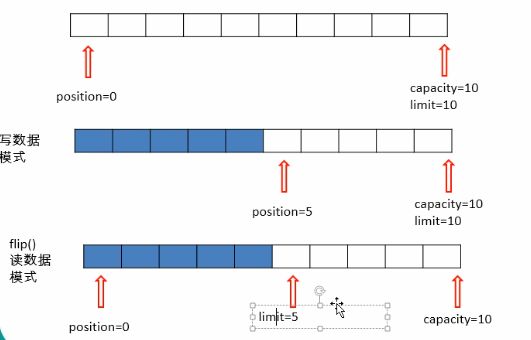
NIO给了我们一个flip()方法。这个方法可以改动position和limit的位置!查看上面输出显示:
- limit变成了position的位置了
- 而position变成了0
看到这里的同学可能就会想到了:当调用完filp()时:limit是限制读到哪里,而position是从哪里读
一般我们称filp()为**“切换成读模式”,每当要从缓存区的时候读取数据时,就调用filp()“切换成读模式”**。
// 创建一个limit()大小的字节数组(因为就只有limit这么多个数据可读)
byte[] bytes = new byte[byteBuffer.limit()];
// 将读取的数据装进我们的字节数组中
byteBuffer.get(bytes);
// 输出数据
System.out.println(new String(bytes, 0, bytes.length));
再次查看4个变量
System.out.println("-----------------get---------------------");
System.out.println("get完之后-->limit--->" + byteBuffer.limit());
System.out.println("get完之后-->position--->" + byteBuffer.position());
System.out.println("get完之后-->capacity--->" + byteBuffer.capacity());
System.out.println("get完之后-->mark--->" + byteBuffer.mark());
运行结果
-----------------get---------------------
get完之后-->limit--->6
get完之后-->position--->6
get完之后-->capacity--->1024
get完之后-->mark--->java.nio.HeapByteBuffer[pos=6 lim=6 cap=1024]
读完我们还想写数据到缓冲区,那就使用clear()函数,这个函数会“清空”缓冲区:
byteBuffer.clear();
System.out.println("-----------------clear---------------------");
System.out.println("clear完之后-->limit--->" + byteBuffer.limit());
System.out.println("clear完之后-->position--->" + byteBuffer.position());
System.out.println("clear完之后-->capacity--->" + byteBuffer.capacity());
System.out.println("clear完之后-->mark--->" + byteBuffer.mark());
运行结果:
-----------------clear---------------------
clear完之后-->limit--->1024
clear完之后-->position--->0
clear完之后-->capacity--->1024
clear完之后-->mark--->java.nio.HeapByteBuffer[pos=0 lim=1024 cap=1024]
注意:数据没有真正被清空,只是被遗忘掉了
Buffer的使用
转载地址:https://www.jianshu.com/p/a9b2fec31fd1
通常遵循四个步骤:
1. 把数据写入buffer;
2. 调用flip;
3. 从Buffer中读取数据;
4. 调用buffer.clear()
当写入数据到buffer中时,buffer会记录已经写入的数据大小。当需要读数据时,通过flip()方法把buffer从写模式调整为读模式;在读模式下,可以读取所有已经写入的数据。
当读取完数据后,需要清空buffer,以满足后续写入操作。清空buffer有两种方式:调用clear(),一旦读完Buffer中的数据,需要让Buffer准备好再次被写入,clear会恢复状态值,但不会擦除数据。
常用方法
在对Buffer进行读/写操作前,我们可以调用Buffer类提供的一些辅助方法来正确设置 position 和 limit 的值,主要有如下几个
- flip(): 设置 limit 为 position 的值,然后 position 置为0。对Buffer进行读取操作前调用。
- rewind(): 仅仅将 position
置0。一般是在重新读取Buffer数据前调用,比如要读取同一个Buffer的数据写入多个通道时会用到。
- clear(): 回到初始状态,即 limit 等于 capacity,position 置0。重新对Buffer进行写入操作前调用。
- compact(): 将未读取完的数据(position 与 limit 之间的数据)移动到缓冲区开头,并将 position
设置为这段数据末尾的下一个位置。其实就等价于重新向缓冲区中写入了这么一段数据。



Channel通道
概述

Channel和传统IO中的Stream很相似。虽然很相似,但是有很大的区别,主要区别为:通道是双向的,通过一个Channel既可以进行读,也可以进行写;而Stream只能进行单向操作,通过一个Stream只能进行读或者写,比如InputStream只能进行读取操作,OutputStream只能进行写操作;
通道是一个对象,通过它可以读取和写入数据,当然了所有数据都通过Buffer对象来处理。我们永远不会将字节直接写入通道中,相反是将数据写入包含一个或者多个字节的缓冲区。同样不会直接从通道中读取字节,而是将数据从通道读入缓冲区,再从缓冲区获取这个字节。
从上述内容可知,一个Channel(通道)代表和某一实体的连接,这个实体可以是文件、网络套接字等。也就是说,通道是Java NIO提供的一座桥梁,用于我们的程序和操作系统底层I/O服务进行交互。
FileChannel用于文件的数据读写。 DatagramChannel用于UDP的数据读写。 SocketChannel用于TCP的数据读写。 ServerSocketChannel允许我们监听TCP链接请求,每个请求会创建会一个SocketChannel。
Channel通道只负责传输数据、不直接操作数据的。操作数据都是通过Buffer缓冲区来进行操作!
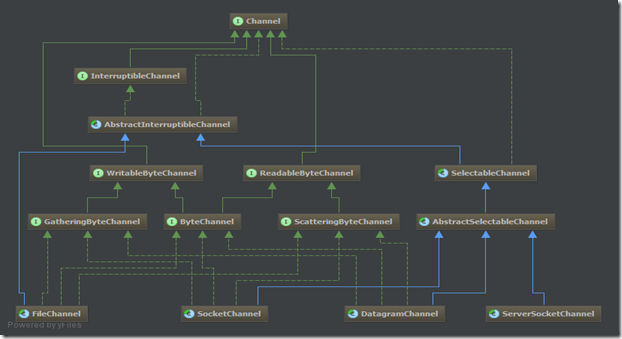
FileChannel
使用通道
打开通道比较简单,除了FileChannel,都用open方法打开。
我们知道,通道是和缓冲区交互的,从缓冲区获取数据进行传输,或将数据传输给缓冲区。从类继承层次结构可以看出,通道一般都是双向的(除FileChannel)。
关闭通道
通道不能被重复使用,这点与缓冲区不同;关闭通道后,通道将不再连接任何东西,任何的读或写操作都会导致ClosedChannelException。
调用通道的close()方法时,可能会导致线程暂时阻塞,就算通道处于非阻塞模式也不例外。如果通道实现了InterruptibleChannel接 口,那么阻塞在该通道上的一个线程被中断时,该通道将被关闭,被阻塞线程也会抛出ClosedByInterruptException异常。当一个通道 关闭时,休眠在该通道上的所有线程都将被唤醒并收到一个AsynchronousCloseException异常。
发散、聚集
发散、聚集,又被称为矢量I/O,简单而强大的概念,它是指在多个缓冲区上实现一个简单的I/O操作。它减少或避免了缓冲区的拷贝和系统调用,它应该使用直接缓冲区以从本地I/O获取最大性能优势。
- Scatter(发散): 从一个Channel读取的信息分散到N个缓冲区中(Buufer).
- Gather(聚集): 将N个Buffer里面内容按照顺序发送到一个Channel.

Socket通道
Socket通道有三个,分别是ServerSocketChannel、SocketChannel和DatagramChannel,而它们又分别对 应java.net包中的Socket对象ServerSocket、Socket和DatagramSocket;Socket通道被实例化时,都会创 建一个对等的Socket对象。
Socket通道可以运行非阻塞模式并且是可选择的,非阻塞I/O与可选择性是紧密相连的,这也正是管理阻塞的API要在 SelectableChannel中定义的原因。设置非阻塞非常简单,只要调用configureBlocking(false)方法即可。如果需要中 途更改阻塞模式,那么必须首先获得blockingLock()方法返回的对象的锁。
ServerSocketChannel
ServerSocketChannel是一个基于通道的socket监听器。但它没有bind()方法,因此需要取出对等的Socket对象并使用它来 绑定到某一端口以开始监听连接。在非阻塞模式下,当没有传入连接在等待时,其accept()方法会立即返回null。正是这种检查连接而不阻塞的能力实 现了可伸缩性并降低了复杂性,选择性也因此得以实现。
SocketChannel
相对于ServerSocketChannel,它扮演客户端,发起到监听服务器的连接,连接成功后,开始接收数据。
要注意的是,调用它的open()方法仅仅是打开但并未连接,要建立连接需要紧接着调用connect()方法;也可以两步合为一步,调用open(SocketAddress remote)方法。 你会发现connect()方法并未提供timout参数,作为替代方案,你可以用isConnected()、isConnectPending()或finishConnect()方法来检查连接状态。
DatagramChannel
不同于前面两个通道对象,它是无连接的,它既可以作为服务器,也可以作为客户端。
常用方法
Channel中最常用的三个类方法就是map、read和write,其中map方法用于将Channel对应的部分或全部数据映射成ByteBuffer,而read或write方法有一系列的重载形式,这些方法用于从Buffer中读取数据或向Buffer中写入数据。
Selector选择器
转载地址:https://www.jianshu.com/p/a9b2fec31fd1
概述
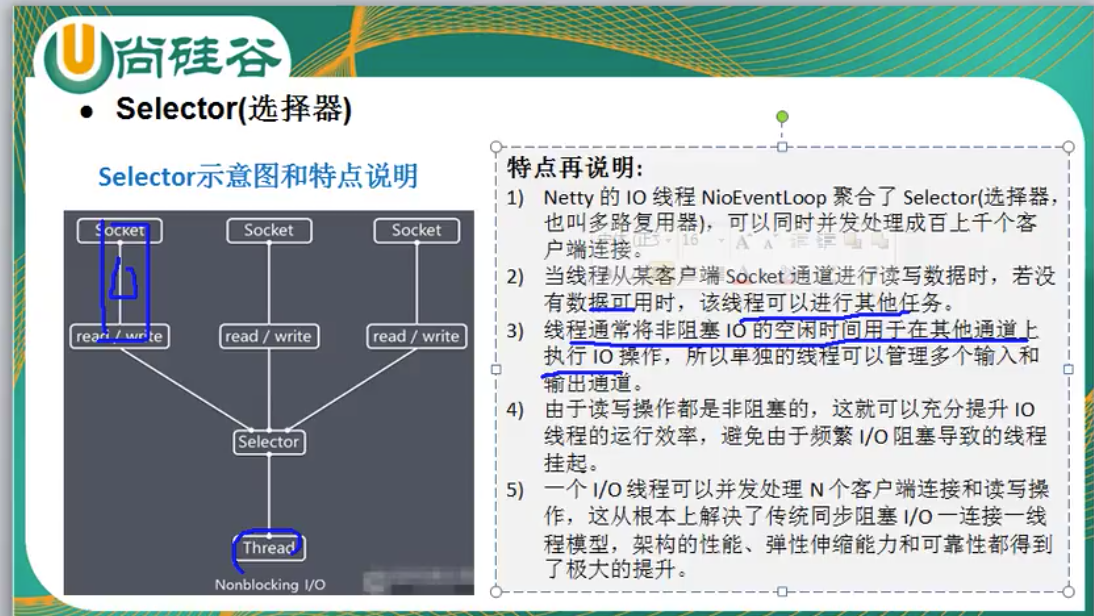
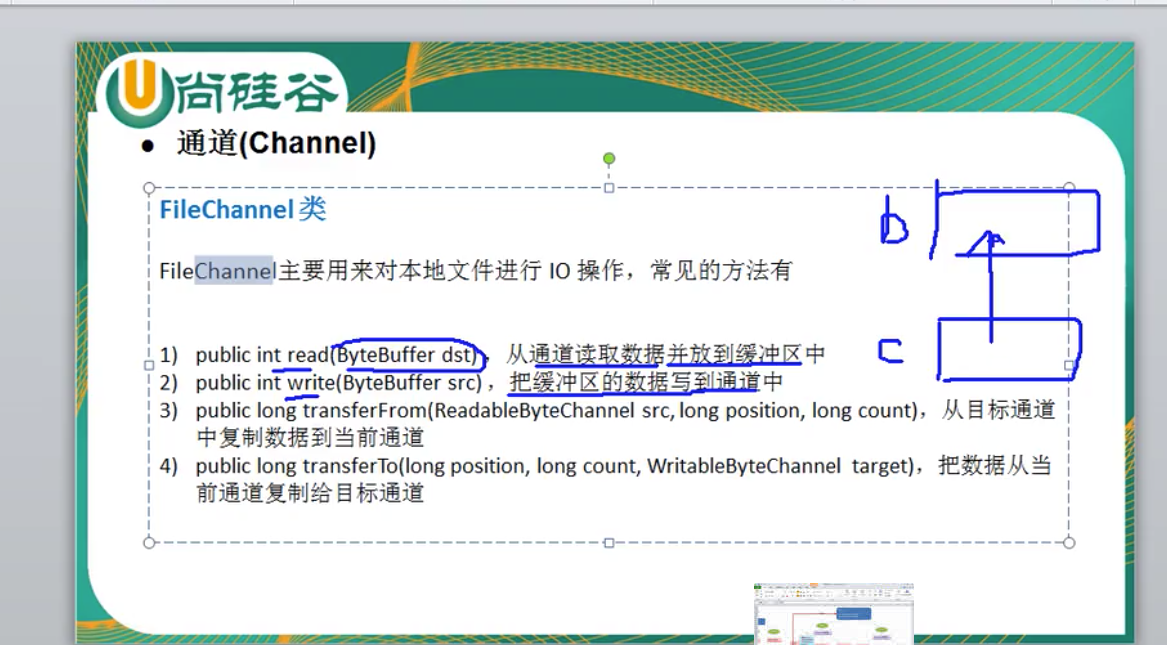
Selector类是NIO的核心类,Selector能够检测多个注册的通道上是否有事件发生,如果有事件发生,便获取事件然后针对每个事件进行相应的响应处理。这样一来,只是用一个单线程就可以管理多个通道,也就是管理多个连接。这样使得只有在连接真正有读写事件发生时,才会调用函数来进行读写,就大大地减少了系统开销,并且不必为每个连接都创建一个线程,不用去维护多个线程,并且避免了多线程之间的上下文切换导致的开销。
与Selector有关的一个关键类是SelectionKey,一个SelectionKey表示一个到达的事件,这2个类构成了服务端处理业务的关键逻辑。
Selector(选择器)是一个特殊的组件,用于采集各个通道的状态(或者说事件)。我们先将通道注册到选择器,并设置好关心的事件,然后就可以通过调用select()方法,静静地等待事件发生。
Selector是Java NIO中的一个组件,用于检查一个或多个NIO Channel的状态是否处于可读、可写。如此可以实现单线程管理多个channels,也就是可以管理多个网络链接。

为什么要用Selector
如果用阻塞I/O,需要多线程(浪费内存),如果用非阻塞I/O,需要不断重试(耗费CPU)。Selector的出现解决了这尴尬的问题,非阻塞模式下,通过Selector,我们的线程只为已就绪的通道工作,不用盲目的重试了。比如,当所有通道都没有数据到达时,也就没有Read事件发生,我们的线程会在select()方法处被挂起,从而让出了CPU资源。
常用方法

使用
创建Selector(Creating a Selector)。创建一个Selector可以通过Selector.open()方法:
Selector selector = Selector.open();
注册Channel到Selector上:
channel.configureBlocking(false);
SelectionKey key = channel.register(selector, SelectionKey.OP_READ);
Channel必须是非阻塞的。FileChannel不适用Selector,因为FileChannel不能切换为非阻塞模式。Socket channel可以正常使用。
四种注册事件
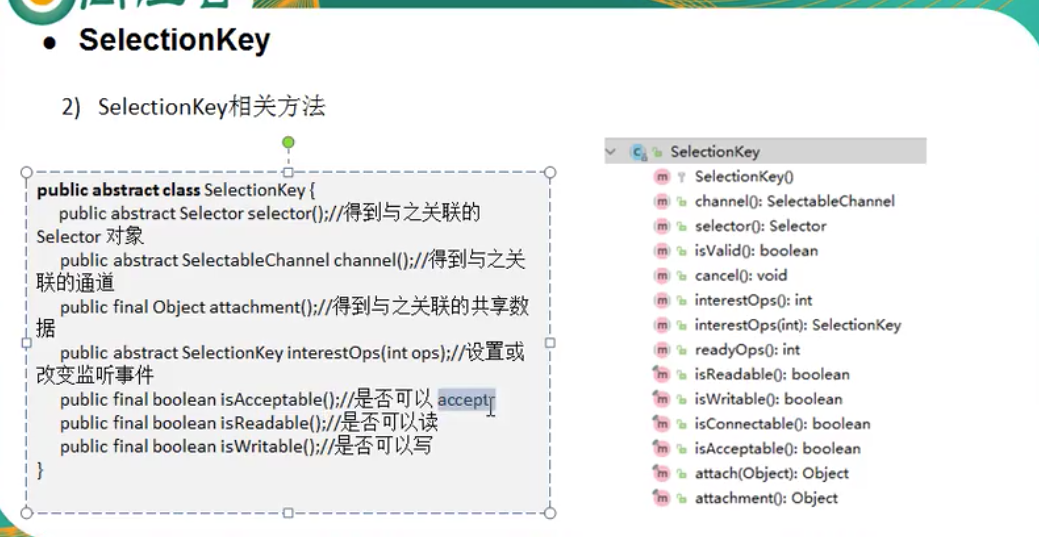
register的第二个参数,这个参数是一个“关注集合”,代表我们关注的channel状态,有四种基础类型可供监听
Accept:有可以接受的连接
Connect:连接成功
Read:有数据可读
Write:可以写入数据了
一个channel触发了一个事件也可视作该事件处于就绪状态。
因此当channel与server连接成功后,那么就是“Connetct”状态。server channel接收请求连接时处于“Accept”状态。channel有数据可读时处于“Read”状态。channel可以进行数据写入时处于“Writer”状态。当注册到Selector的所有Channel注册完后,调用Selector的select()方法,将会不断轮询检查是否有以上设置的状态产生,如果产生便会加入到SelectionKey集合中,进行后续操作。
上述的四种就绪状态用SelectionKey中的常量表示如下:
SelectionKey.OP_CONNECT
SelectionKey.OP_ACCEPT
SelectionKey.OP_READ
SelectionKey.OP_WRITE
从Selector中选择channel(Selecting Channels via a Selector)
一旦我们向Selector注册了一个或多个channel后,就可以调用select来获取channel。select方法会返回所有处于就绪状态的channel。
select方法具体如下:
int select()
int select(long timeout)
int selectNow()
select()方法在返回channel之前处于阻塞状态。 select(long timeout)和select做的事一样,不过他的阻塞有一个超时限制。
selectNow()不会阻塞,根据当前状态立刻返回合适的channel。
select()方法的返回值是一个int整形,代表有多少channel处于就绪了。也就是自上一次select后有多少channel进入就绪。
举例来说,假设第一次调用select时正好有一个channel就绪,那么返回值是1,并且对这个channel做任何处理,接着再次调用select,此时恰好又有一个新的channel就绪,那么返回值还是1,现在我们一共有两个channel处于就绪,但是在每次调用select时只有一个channel是就绪的。
selectedKeys()
在调用select并返回了有channel就绪之后,可以通过选中的key集合来获取channel,这个操作通过调用selectedKeys()方法:
Set<SelectionKey> selectedKeys = selector.selectedKeys();
遍历这些SelectionKey可以通过如下方法:
Set<SelectionKey> selectedKeys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = selectedKeys.iterator();
while(keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if(key.isAcceptable()) {
// a connection was accepted by a ServerSocketChannel.
} else if (key.isConnectable()) {
// a connection was established with a remote server.
} else if (key.isReadable()) {
// a channel is ready for reading
} else if (key.isWritable()) {
// a channel is ready for writing
}
keyIterator.remove();
}
上述循环会迭代key集合,针对每个key我们单独判断他是处于何种就绪状态。
注意keyIterater.remove()方法的调用,Selector本身并不会移除SelectionKey对象,这个操作需要我们收到执行。当下次channel处于就绪是,Selector任然会把这些key再次加入进来。
SelectionKey.channel返回的channel实例需要强转为我们实际使用的具体的channel类型,例如ServerSocketChannel或SocketChannel.
wakeUp()
由于调用select而被阻塞的线程,可以通过调用Selector.wakeup()来唤醒即便此时已然没有channel处于就绪状态。具体操作是,在另外一个线程调用wakeup,被阻塞与select方法的线程就会立刻返回。
close()
当操作Selector完毕后,需要调用close方法。close的调用会关闭Selector并使相关的SelectionKey都无效。channel本身不管被关闭。
完整Selector实例
Selector selector = Selector.open();
channel.configureBlocking(false);
SelectionKey key = channel.register(selector, SelectionKey.OP_READ);
while(true) {
int readyChannels = selector.select();
if(readyChannels == 0) continue;
Set<SelectionKey> selectedKeys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = selectedKeys.iterator();
while(keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if(key.isAcceptable()) {
// a connection was accepted by a ServerSocketChannel.
} else if (key.isConnectable()) {
// a connection was established with a remote server.
} else if (key.isReadable()) {
// a channel is ready for reading
} else if (key.isWritable()) {
// a channel is ready for writing
}
keyIterator.remove();
}
}
使用流程

selector的wakeup理解
转载地址:https://www.hxlzpnyist.site/2017/12/21/NIO-selector%E7%9A%84wakeup/
某个线程调用select()方法后阻塞了,即使没有通道已经就绪,也有办法让其从select()方法返回。只要让其它线程在第一个线程调用select()方法的那个对象上调用Selector.wakeup()方法即可。阻塞在select()方法上的线程会立马返回。
如果有其它线程调用了wakeup()方法,但当前没有线程阻塞在select()方法上,下个调用select()方法的线程会立即“醒来(wake up)”
代码测试
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.util.concurrent.TimeUnit;
public class NioWakeUp {
private Selector selector;
public void start() throws IOException {
// 开启选择器 selector
selector = Selector.open();
// 开启服务端 socket 通道
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
// 设置为非阻塞
serverSocketChannel.configureBlocking(false);
// 绑定服务端端口
serverSocketChannel.socket().bind(new InetSocketAddress(8888));
// 通道注册到选择器上 并监听 接收客户端事件
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
// 因 selector.select 会阻塞当前线程 故异步处理
new Thread(new Runnable() {
@Override
public void run() {
while (true) {
System.out.println("select 前执行");
try {
selector.select();
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("select 后执行");
}
}
}).start();
}
public void wakeup() {
System.out.println("开始唤醒");
selector.wakeup();
}
public static void main(String[] args) throws IOException, InterruptedException {
final NioWakeUp app = new NioWakeUp();
app.start();
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
while (true) {
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
app.wakeup();
}
}
});
thread.start();
thread.join();
}
}
运行结果
select----->前执行
开始唤醒
select----->后执行
select----->前执行
开始唤醒
select----->后执行
select----->前执行
开始唤醒
select----->后执行
select----->前执行
开始唤醒
select----->后执行
select----->前执行
开始唤醒
select----->后执行
select----->前执行
开始唤醒
select----->后执行
select----->前执行
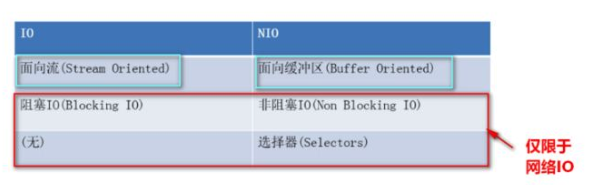
NIO vs IO
学习了NIO之后我们都会有这样一个疑问:到底什么时候该用NIO,什么时候该用传统的I/O呢?
其实了解他们的特性后,答案还是比较明确的,NIO擅长1个线程管理多条连接,节约系统资源,但是如果每条连接要传输的数据量很大的话,因为是同步I/O,会导致整体的响应速度很慢;而传统I/O为每一条连接创建一个线程,能充分利用处理器并行处理的能力,但是如果连接数量太多,内存资源会很紧张。
总结就是:连接数多数据量小用NIO,连接数少用I/O(写起来也简单- -)。
IO是面向流的,NIO是面向缓冲区的
-
Java IO面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方;
-
NIO则能前后移动流中的数据,因为是面向缓冲区的
IO流是阻塞的,NIO流是不阻塞的
-
Java IO的各种流是阻塞的。这意味着,当一个线程调用read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了
-
Java NIO的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取。NIO可让您只使用一个(或几个)单线程管理多个通道(网络连接或文件),但付出的代价是解析数据可能会比从一个阻塞流中读取数据更复杂。
-
非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。
选择器
- Java NIO的选择器允许一个单独的线程来监视多个输入通道,你可以注册多个通道使用一个选择器,然后使用一个单独的线程来“选择”通道:这些通道里已经有可以处理的输入,或者选择已准备写入的通道。这种选择机制,使得一个单独的线程很容易来管理多个通道。
Selector, Channel Buffer 关系图

问题
1. FileChannel无法设置为非阻塞模式的原因
在SelectableChannel中有configureBlocking方法,AbstractInterruptibleChannel中没有此方法,FileChannel类中也没有此方法。所以从源码的角度分析FileChannel不能切换到非阻塞模式,这就是原因。
2. SelectionKey.cancel(); 取消读事件的监控
链接:https://juejin.im/post/5da960185188257a63539646
无论通过channel.close()还是通过selectionKey.cancel()来取消一个selectionKey ,这个selectionKey都会被立即添加到selector的 cancelled-key set 中,但是所关联的channel并没有立即被撤销登记,直到发生下次 selection operations, 这些channel才被从selector中撤销登记,与此同时这些Cancelled keys才会被从这个selector的所有selectionKey set(可能是_key set_、selected-key set、cancelled-key set)中移除,但是不会影响这些集合本身。
3. SocketChannel.register()和key.interestOps()之间的区别
在这个SO问题中找到的echo NIO服务器中 ,对于每个接受的密钥,都会调用一个寄存器来进行读操作。 然后,一旦读取消息,就再次调用寄存器以进行写操作。 但是,在写入消息之后,不是注册另一个读取操作,而是调用key.interestOps(SelectionKey.OP_READ) 。为什么用这个了?
register()将丢失或更改密钥附件,并可能完全返回一个新的SelectionKey :未指定。 在这种情况下使用interestOps()` 。
4. 完全理解NIO Selector
好文:https://juejin.im/post/5da960185188257a63539646
5. BIO和NIO对比
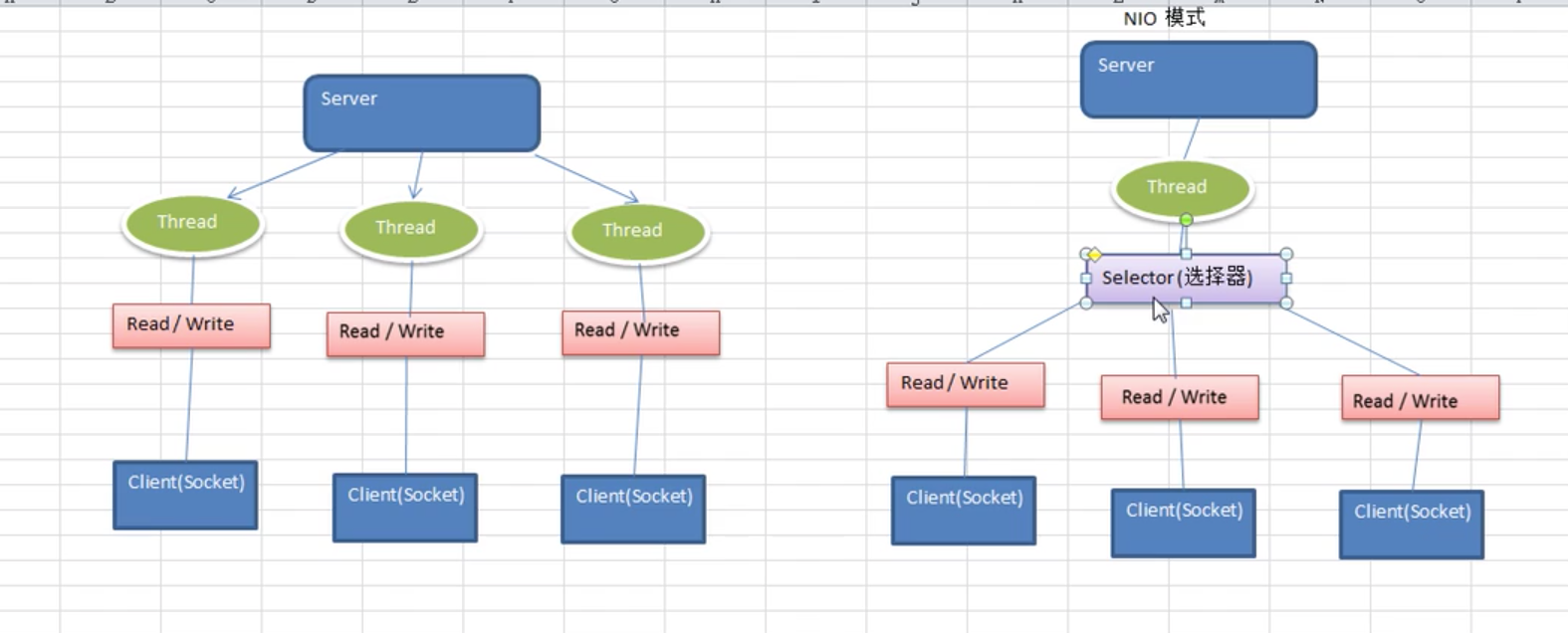
也可以多个线程来接受。
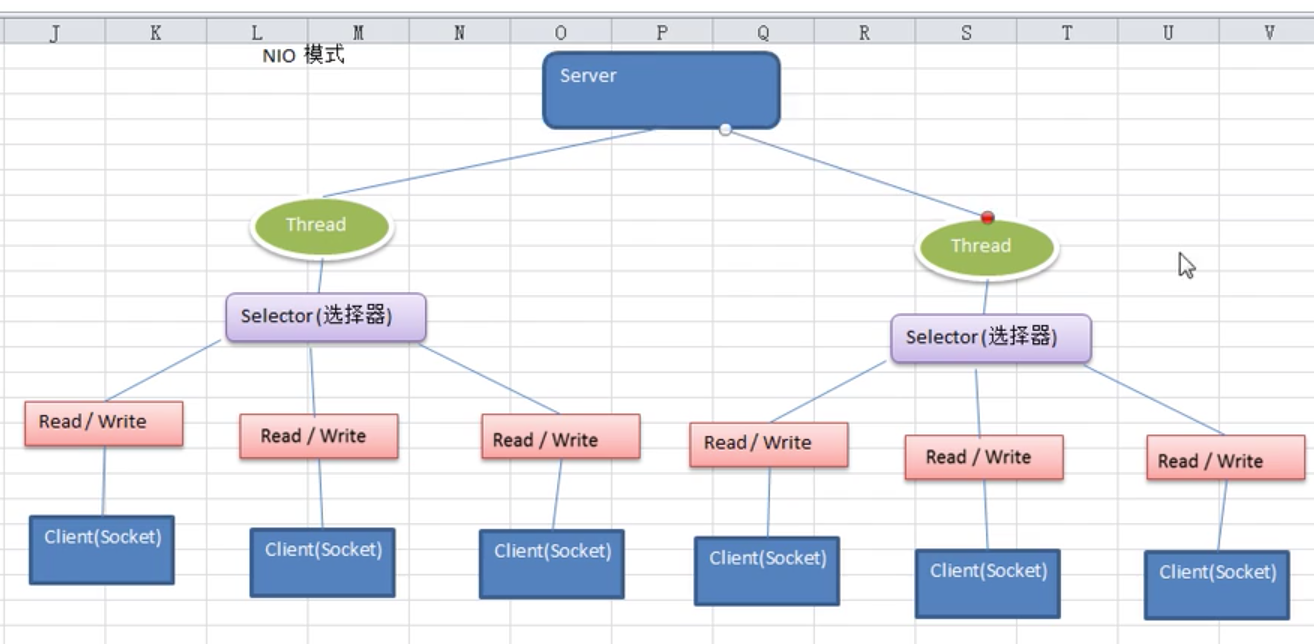


6. 如何理解他是非阻塞和阻塞的关系

可以看到,等1秒后,就不等了,可以做其他的事情去了。
「真诚赞赏,手留余香」

真诚赞赏,手留余香
使用微信扫描二维码完成支付
