[TOC]
转载:https://www.jianshu.com/p/048d93d3ee54
转载:https://zhuanlan.zhihu.com/p/150420895
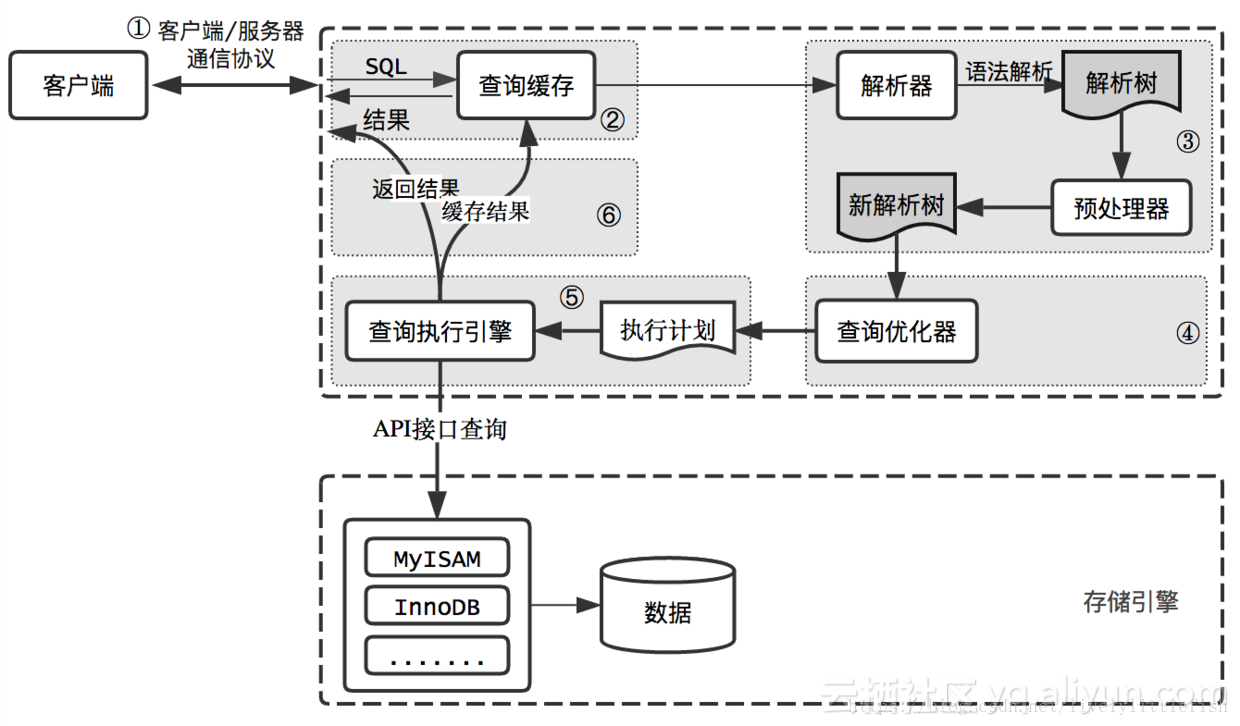
sql执行流程
优化思路
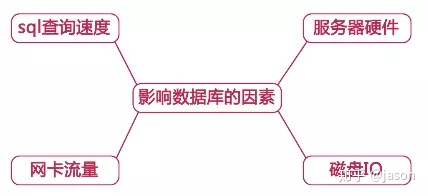
索引优化,查询优化,查询缓存,服务器设置优化,操作系统和硬件优化,应用层面优化(web服务器,缓存)等等。对于一个整体项目而言只有这些齐头并进,才能实现mysql高性能。
方向
- SQL优化方向:执行计划、索引、SQL改写。
- 架构优化方向:高可用架构、高性能架构、分库分表, 分区。
Join查询
Join执行过程
在MySQL中,A left join B on condition 的执行过程如下:
- 以 table_A 为驱动表,检索 table_B
- 根据 on 条件过滤 table_B 的数据,构建 table_A 结果集,并且添加外部行。
- 对结果集执行 where 条件过滤。如果A中有一行匹配 where 子句但是B中没有一行匹配on条件,则生成另一个B行,其中所有列设置为NULL。
- 执行 group by 语句分组
- 执行 having 语句对分组结果筛选
- 执行 select 出结果集。
- 执行 distinct 对结果去重
- 执行 order by 语句
- 执行 limit 语句
上面需要注意的重点是:MySQL会先进行连接查询,然后再使用where子句查询结果,再从结果执行order by。所以如果被驱动表数据过大,会造成检索行过多。可以利用子查询先查询出一个较小的结果集,然后再用连接驱动。
NLJ算法
在MySQL中,只有一种 join 算法,就是 Nested Loop Join(嵌套循环连接),它没有其他很多数据库锁提供的 Hash Join,也没有Sort Merge Join。
没错,MySQL使用了一种算法去优化它:Nested-Loop Join(嵌套循环连接),但是这个算法有三个变种,分别是
Simple Nested-Loop Join 简单嵌套循环连接
Index Nested-Loop Join 索引嵌套循环连接
Block Nested-Loop Join 块索引嵌套连接
简单嵌套循环连接
所谓简单嵌套循环连接,其实真的很简单,就是啥都不做,利用循环嵌套对join的所有表逐一去遍历。如下两个表,以t1作为驱动表,遍历到元素a时,从被驱动表t2中匹配与a相等的行,并将匹配结果存储到结果集中,这种方法的效率无疑是非常低的,其时间复杂度O(n) = t1 * t2,真的做了一次笛卡尔乘积。
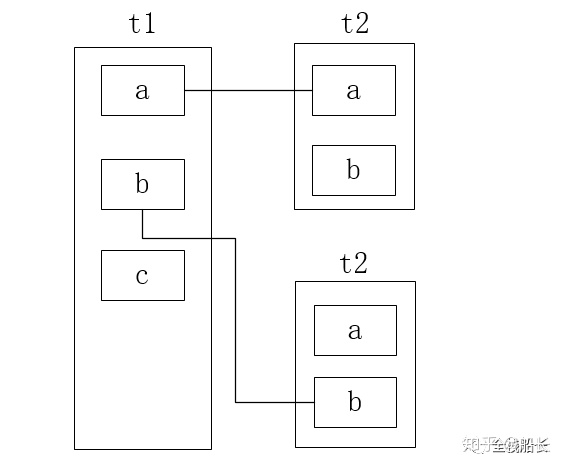
上面的查询逻辑的伪代码如下
for(M id : main){
for(S main_id : second){
if(id==main_id){
//添加到结果集
}
}
}
我们可以思考一下,这两层循环可以怎么去优化它呢?
说到mysql的优化,我们的第一个念头肯定就是加索引。没错,我们可以通过减少循环次数来达到优化的效果。例如被驱动表t2中的字段加了索引,而这个字段刚好就是驱动表t1中遍历的那个字段,那岂不是美滋滋?直接拿这个字段的值去被驱动表t2中取值不就得了。下面这个算法就是根据索引进行的优化
索引嵌套循环连接
如果上面的解释还不是十分明白,我们可以通过伪代码来理解
//假如有两个表,主表main和从表second,主键均是id且second表的main_id加了索引
select m.* from main m
inner join second s on s.main_id = m.id
执行上面这条查询语句时的取值代码类似下面
for(M id : main){
if(second.contains(id)){
//添加到结果集
}
}
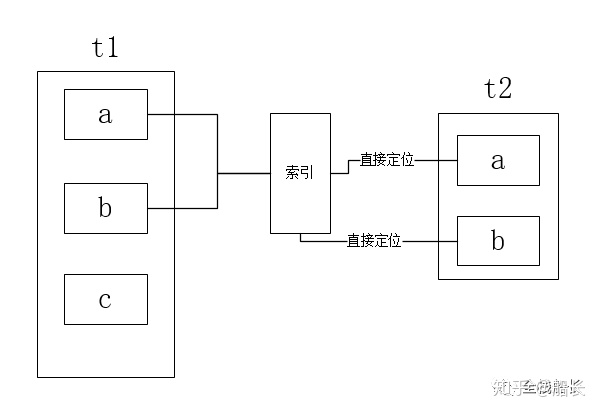
从代码层面来看,我们马上就能感受到循环次数的量级变化,但是其实拿id去匹配被驱动表second时,还是会有一个回表的操作,降低了效率。
块嵌套循环连接
如果join后面的条件不是索引列表怎么办呢?使用简单嵌套循环连接是不可能的,这辈子都不可能的了。
mysql使用了一个叫join buffer的缓冲区去减少循环次数,这个缓冲区默认是256KB,可以通过命令show variables like ‘join_%‘查看
其具体的做法是,将驱动表t1中符合条件的列一次性查询到缓冲区中,然后遍历一次被驱动表t2,并逐一和缓冲区的所有值比较,将比较结果加入结果集中
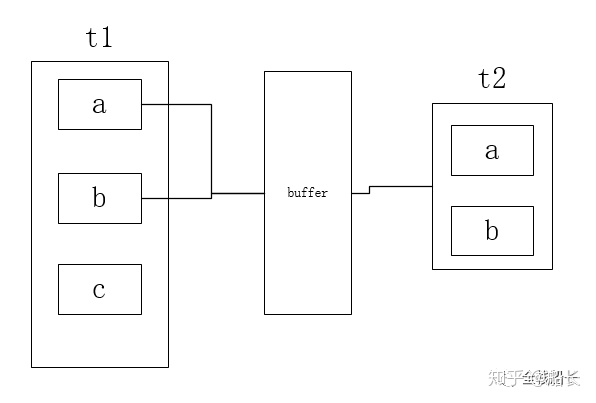
这里直接用文字描述可能有点晦涩难懂,那还是举一个例子,大家肯定立马就懂了
假设t1表中有100行记录,t2表中有50行记录,而块嵌套循环算法会每次读取t1表中的10条记
录,并加入到缓冲区buffer中。然后遍历一次t2表,对于t2表中的每行记录,都会与与buffer
中的10条记录进行比较,并将相等的加入结果集。如此一来,循环次数变为10*50=500次
驱动表
就是在嵌套循环和哈希连接中,用来最先获得数据,并以此表为依据,逐步获得其他表的数据,直至最终查询到所有安祖条件的数据的第一个表。
驱动表不一定是表,也可以是一个数据集,即由某个表中满足条件的数据行组成的子集合。(同理被驱动表也不一定非得是表,也可以是一个数据集)
索引嵌套联系由于被驱动表上有索引,所以比较的时候不再需要逐条进行比较,而可以通过拿两个表关联字段的索引来进行比较,从而加速查询。这也就是平时我们在做关联查询的时候必须要求关联字段有索引的一个主要原因。
这种算法在连接查询的时候,驱动表会根据关联字段的索引进行查找,当在索引上找到了符合值,再回表进行查询。也就是只有当匹配到索引以后才会进行回表。回表博客文章《mysql系列-覆盖索引与回表》
根据NLJ算法可知,我们在进行连接查询的时候,应该尽可能的使用小表做为驱动表,这样可以显著减小循环的次数。
示例
例如,表连接返回一条记录,存在2张表,一个10条记录,一个1000万条记录,若2表都存在连接字段索引。
- . 以小表为驱动表,则代价为:10*(通过索引在大表查询一条记录的代价); 2). 以大表为驱动表,则代价为:1000万*(通过索引在小表查询一条记录的代价)。
由上面1可以看出, 在被驱动表建立索引可以加快速度。
查询和索引优化
- 用小结果集驱动大结果集,尽量减少 join 语句中的Nested Loop循环总次数。
- 优先优化 Nested Loop 内层循环,因为内层循环是循环中执行次数最多的,每次循环提升很小的性能都能在整个循环中提升很大的性能。
- 对被驱动表的 join 字段上建立索引,并且Join ON 条件的字段应该是相同类型的。
- 当被驱动表的 join 字段上无法建立索引的时候,设置足够的 Join Buffer Size。
说明:跟多相关看博客《mysql系列-索引设计和查询优化》
更新优化
- 如果只更改1、2个字段,不要Update全部字段,否则频繁调用会引起明显的性能消耗,同时带来大量日志;
- 对于多张大数据量(这里几百条就算大了)的表JOIN,要先分页再JOIN,否则逻辑读会很高,性能很差。
- 应尽可能的避免更新 clustered 索引数据列,因为 clustered 索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。若应用系统需要频繁更新 clustered 索引数据列, 那么需要考虑是否应将该索引建为 clustered 索引;
插入优化
-
在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log,
以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert。
-
拆分大的 DELETE 或INSERT 语句,批量提交SQL语句。
如果你需要在一个在线的网站上去执行一个大的 DELETE 或 INSERT 查询,你需要非常小心,要避免你的操作让你的整个网站停止相应。
因为这两个操作是会锁表的,表一锁住了,别的操作都进不来了。Apache 会有很多的子进程或线程。所以,其工作起来相当有效率,而我们的服务器也不希望有太多的子进程,线程和数据库链接,这是极大的占服务器资源的事情,尤其是内存。
如果你把你的表锁上一段时间,比如30秒钟,那么对于一个有很高访问量的站点来说,这30秒所积累的访问进程/线程,数据库链接,打开的文件数,可能不仅仅会让你的WEB服务崩溃,还可能会让你的整台服务器马上挂了。 所以,如果你有一个大的处理,你一定把其拆分,使用 LIMIT oracle(rownum),sqlserver(top)条件是一个好的方法。
-
创建适当的索引,每当为一个表添加一个索引,select会更快,可insert和delete却大大变慢,因为创建了维护索引需要许多额外的工作。
1)采用函数处理的字段不能利用索引 2)条件内包括了多个本表的字段运算时不能进行索引
批量插入示例
UPDATE
party_communitya_ssociation_member
SET
job = CASE
WHEN ID = ? THEN ?
WHEN ID = ? THEN ?
WHEN ID = ? THEN ? END,
NAME = CASE
WHEN ID = ? THEN ?
WHEN ID = ? THEN ?
WHEN ID = ? THEN ?
END,
phoneNumber = CASE
WHEN ID = ? THEN ?
WHEN ID = ? THEN ?
WHEN ID = ? THEN ?
END,
identityCard = CASE
WHEN ID = ? THEN ?
WHEN ID = ? THEN ?
WHEN ID = ? THEN ?
END
WHERE
ID IN (?, ?, ?)
「真诚赞赏,手留余香」

真诚赞赏,手留余香
使用微信扫描二维码完成支付
