[TOC]
说明: 文章里面的图片来源地址:https://www.imooc.com/learn/194,教学视频
schema是什么
原文:https://blog.csdn.net/hpulfc/article/details/79564790
在SQL环境下,schema就是数据库对象的集合,所谓的数据库对象也就是常说的表,索引,视图,存储过程等。在schema之上的,就是数据库的实例,也就是通常create databases获得的东西。也就是说一个schema 实例 可以有多个schema, 可以给不同的用户创建不同的schema,并且他们都是在同一数据库实例下面。
在MySQL中基本认为schema和数据库相同,也就是说schema的名称和数据库的实例的名称相同,一个数据库有一个schema。
而在PostgreSQL中,可以创建一个数据库,然后在数据库中,创建不同的schema,每个schema又有着一些各自的表,索引等。
数据库事物
转载地址: https://www.cnblogs.com/huanongying/p/7021555.html
MySQL事务隔离级别
转载地址:https://blog.csdn.net/xuheng8600/article/details/79869669
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交(read-uncommitted) | 是 | 是 | 是 |
| 不可重复读(read-committed) | 否 | 是 | 是 |
| 可重复读(repeatable-read) | 否 | 否 | 是 |
| 串行化(serializable) | 否 | 否 | 否 |
事物级别查看和修改
#查看当前会话隔离级别
SELECT @@tx_isolation
#设置当前会话隔离级别
set session transaction isolation level repeatable read;
#查看系统当前隔离级别
select @@global.tx_isolation;
#查看系统当前隔离级别
set global transaction isolation level repeatable read;
表空间
转载地址:https://blog.csdn.net/daohengshangqian/article/details/50116493
mysql 表空间管理与共享维护,INNODB 对于表的存储有两种形式,一种是共享表空间,及多张表放在一个文件中,还有一种是独立表空间,每个表都有独立的数据文件。
共享表空间
查看当前共享表空间
show variables like '%innodb_data_file_path%' ;
增加共享表空间
[root@localhost mysql]# cat /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
user=mysql
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
innodb_data_file_path=ibdata1:12M;ibdata2:24M:autoextend
更改后,可以再来查来执行 show variables like ‘%innodb_data_file_path%’ ;
独立表空间
show variables like '%innodb_file_per_table%' ;
索引
原文地址: https://www.cnblogs.com/bypp/p/7755307.html
什么是索引?
一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,因此对查询语句的优化显然是重中之重。说起加速查询,就不得不提到索引了。
为什么要有索引呢?
索引在MySQL中也叫做“键”,是存储引擎用于快速找到记录的一种数据结构。索引对于良好的性能,非常关键,尤其是当表中的数据量越来越大时,索引对于性能的影响愈发重要。索引优化应该是对查询性能优化最有效的手段了。索引能够轻易将查询性能提高好几个数量级。索引相当于字典的音序表,如果要查某个字,如果不使用音序表,则需要从几百页中逐页去查。
索引类型
常规索引
常规索引,也叫普通索引(index或key),它可以常规地提高查询效率。一张数据表中可以有多个常规索引。常规索引是使用最普遍的索引类型,如果没有明确指明索引的类型,我们所说的索引都是指常规索引。
主键索引
主键索引(Primary Key),也简称主键。它可以提高查询效率,并提供唯一性约束。一张表中只能有一个主键。被标志为自动增长的字段一定是主键,但主键不一定是自动增长。一般把主键定义在无意义的字段上(如:编号),主键的数据类型最好是数值。
唯一索引
唯一索引(Unique Key),可以提高查询效率,并提供唯一性约束。一张表中可以有多个唯一索引。
全文索引
全文索引(Full Text),可以提高全文搜索的查询效率,一般使用Sphinx替代。但Sphinx不支持中文检索,Coreseek是支持中文的全文检索引擎,也称作具有中文分词功能的Sphinx。实际项目中,我们用到的是Coreseek。
外键索引
外键索引(Foreign Key),简称外键,它可以提高查询效率,外键会自动和对应的其他表的主键关联。外键的主要作用是保证记录的一致性和完整性。
创建/删除索引
语法
#方法一:创建表时
CREATE TABLE 表名 (
字段名1 数据类型 [完整性约束条件…],
字段名2 数据类型 [完整性约束条件…],
[UNIQUE | FULLTEXT | SPATIAL ] INDEX | KEY
[索引名] (字段名[(长度)] [ASC |DESC])
);
#方法二:CREATE在已存在的表上创建索引
CREATE [UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名
ON 表名 (字段名[(长度)] [ASC |DESC]) ;
#方法三:ALTER TABLE在已存在的表上创建索引
ALTER TABLE 表名 ADD [UNIQUE | FULLTEXT | SPATIAL ] INDEX
索引名 (字段名[(长度)] [ASC |DESC]) ;
#删除索引:DROP INDEX 索引名 ON 表名字;
demo实例
创建索引
-在创建表时就创建(需要注意的几点)
create table s1(
id int ,#可以在这加primary key
#id int index #不可以这样加索引,因为index只是索引,没有约束一说,
#不能像主键,还有唯一约束一样,在定义字段的时候加索引
name char(20),
age int,
email varchar(30)
#primary key(id) #也可以在这加
index(id) #可以这样加
);
-在创建表后在创建
create index name on s1(name); #添加普通索引
create unique age on s1(age);添加唯一索引
alter table s1 add primary key(id); #添加住建索引,也就是给id字段增加一个主键约束
create index name on s1(id,name); #添加普通联合索引
删除索引
drop index id on s1;
drop index name on s1; #删除普通索引
drop index age on s1; #删除唯一索引,就和普通索引一样,不用在index前加unique来删,直接就可以删了
alter table s1 drop primary key; #删除主键(因为它添加的时候是按照alter来增加的,那么我们也用alter来删)
mysql三种虚拟表
-
临时表
-
内存表
-
视图
临时表
原文:https://blog.csdn.net/qq_41376740/article/details/79393943
什么是临时表
MySQL用于存储一些中间结果集的表,临时表只在当前连接可见,当关闭连接时,Mysql会自动删除表并释放所有空间。为什么会产生临时表:一般是由于复杂的SQL导致临时表被大量创建。临时表是建立在系统临时文件夹中的表。临时表的数据和表结构都存储在内存之中,退出的时候所占的空间会被释放
临时表的应用场景
当工作在十分大的表上运行时,运行相关查询,来获的一个大量数据的小的子集。较好的办法,不是对整个表运行这些查询,而是让MySQL每次找出所需的少数记录,将记录选择到一个临时表,然后对这些表运行查询。
创建临时表
关键字为temporary
create temporary table tmp_table(
name varchar(10) not null,
value int not null
);
注意:
show tables;
show table status
这两个命令无法查看临时表。 但是可以查内存表
直接将查询结果导入临时表
CREATE TEMPORARY TABLE tmp_table SELECT * FROM table_name
视图
原文:https://www.cnblogs.com/sustudy/p/4166714.html
作用
基本表的内容是持久的,而视图的内容是在使用过程中动态产生的。
视图根本用途看来就一个:简化sql查询,提高开发效率。如果说还有另外一个用途那就是兼容老的表结构。
提高了重用性
提高了重用性,就像一个函数。如果要频繁获取user的name和goods的name。就应该使用以下sql语言。示例:
select a.name as username, b.name as goodsname from user as a, goods as b, ug as c where a.id=c.userid and c.goodsid=b.id;
但有了视图就不一样了,创建视图other。示例
create view other as select a.name as username, b.name as goodsname from user as a, goods as b, ug as c where a.id=c.userid and c.goodsid=b.id;
创建好视图后,就可以这样获取user的name和goods的name。示例:
select * from other;
以上sql语句,就能获取user的name和goods的name了。
对数据库重构,却不影响程序的运行
对数据库重构,却不影响程序的运行。假如因为某种需求,需要将user拆房表usera和表userb,该两张表的结构如下:
测试表:usera有id,name,age字段
测试表:userb有id,name,sex字段
这时如果php端使用sql语句:select * from user;那就会提示该表不存在,这时该如何解决呢。
解决方案:创建视图。以下sql语句创建视图:
create view user as select a.name,a.age,b.sex from usera as a, userb as b where a.name=b.name;
以上假设name都是唯一的。此时php端使用sql语句:select * from user;就不会报错什么的。这就实现了更改数据库结构,不更改脚本程序的功能了。
提高了安全性能。可以对不同的用户
提高了安全性能。可以对不同的用户,设定不同的视图。例如:某用户只能获取user表的name和age数据,不能获取sex数据。则可以这样创建视图。示例如下:
create view other as select a.name, a.age from user as a;
这样的话,使用sql语句:select * from other; 最多就只能获取name和age的数据,其他的数据就获取不了了。
让数据更加清晰
让数据更加清晰。想要什么样的数据,就创建什么样的视图。经过以上三条作用的解析,这条作用应该很容易理解了吧
分库分表


数据库设计
范式化和反范式化
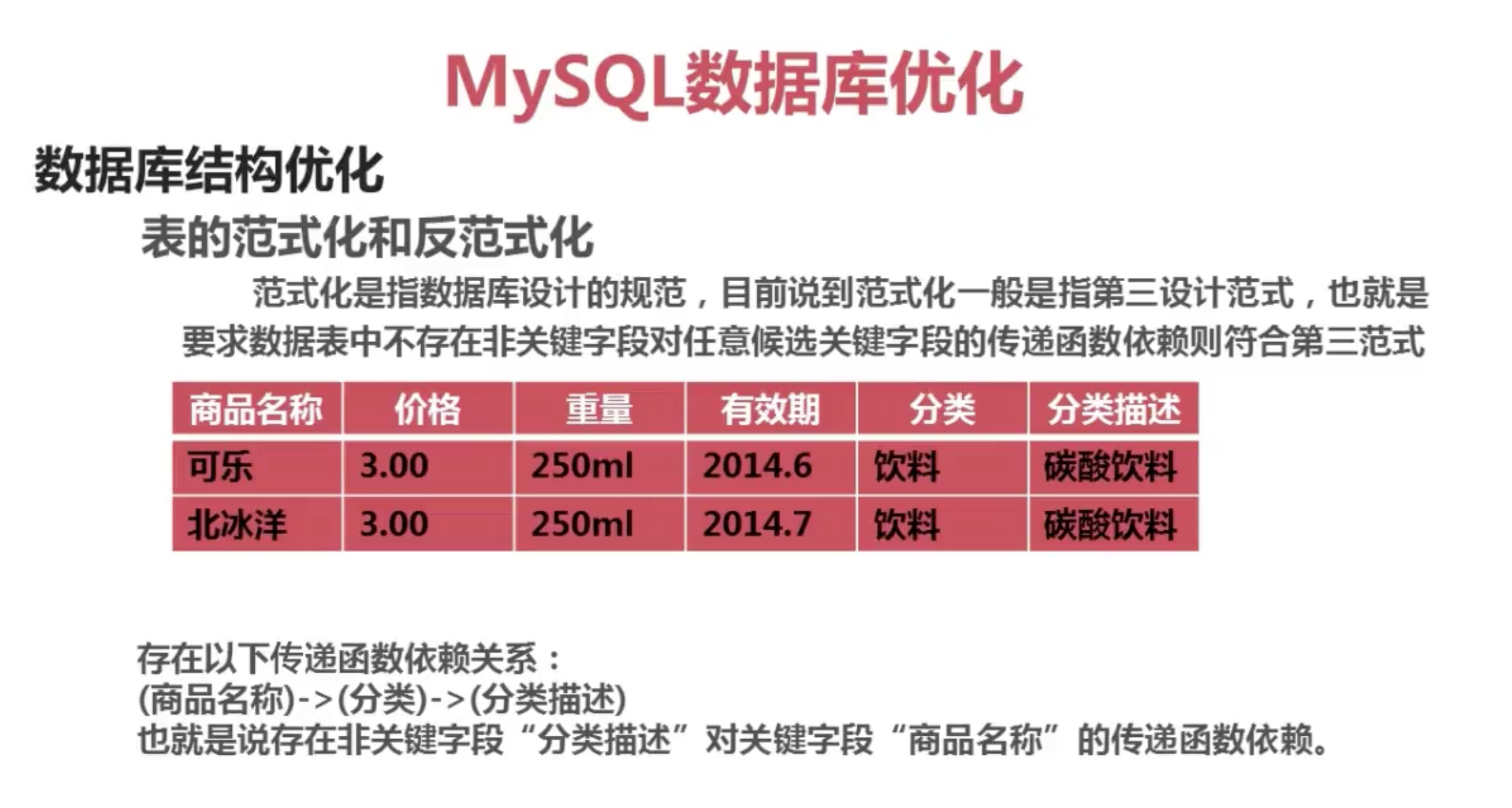
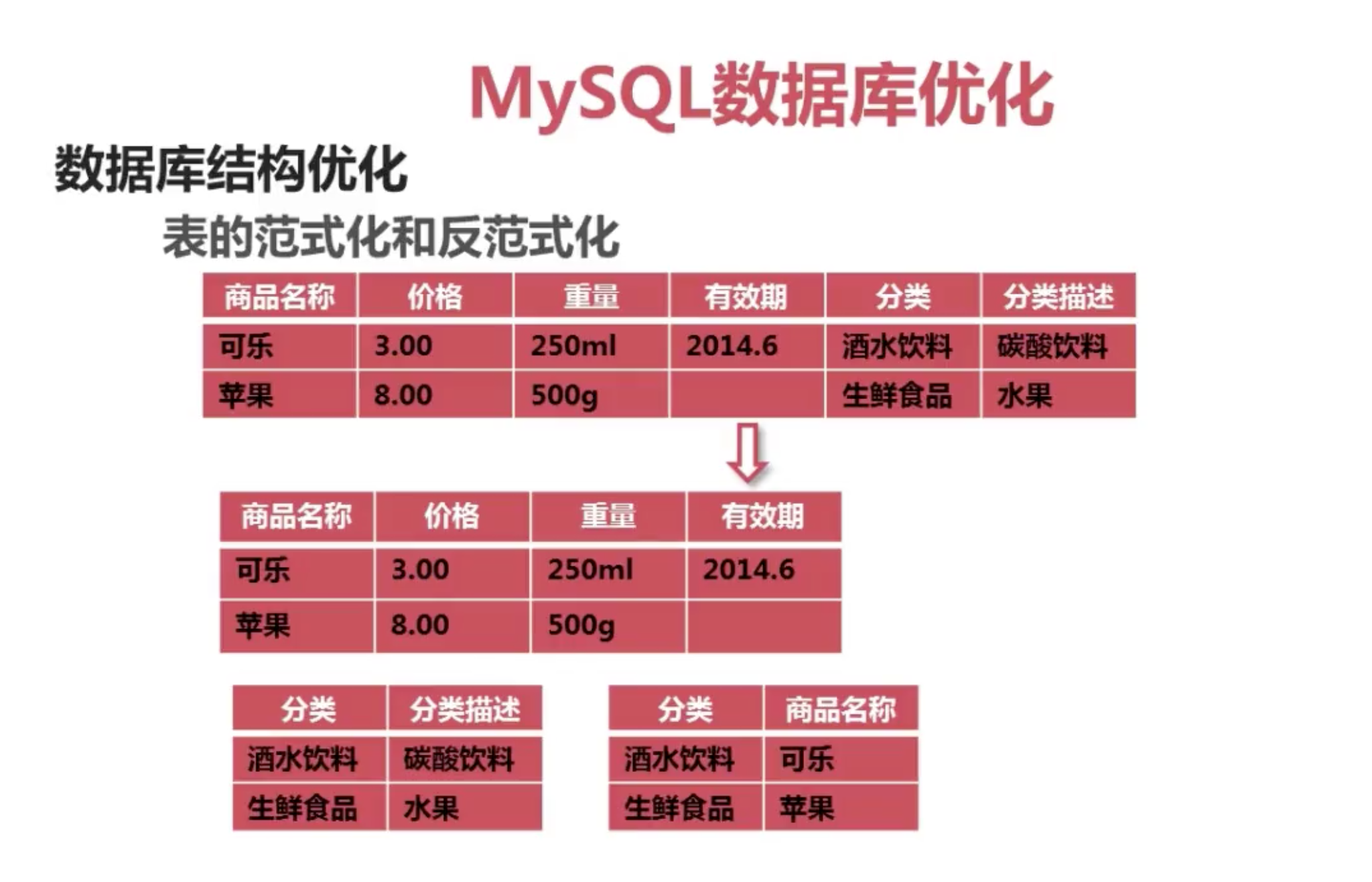
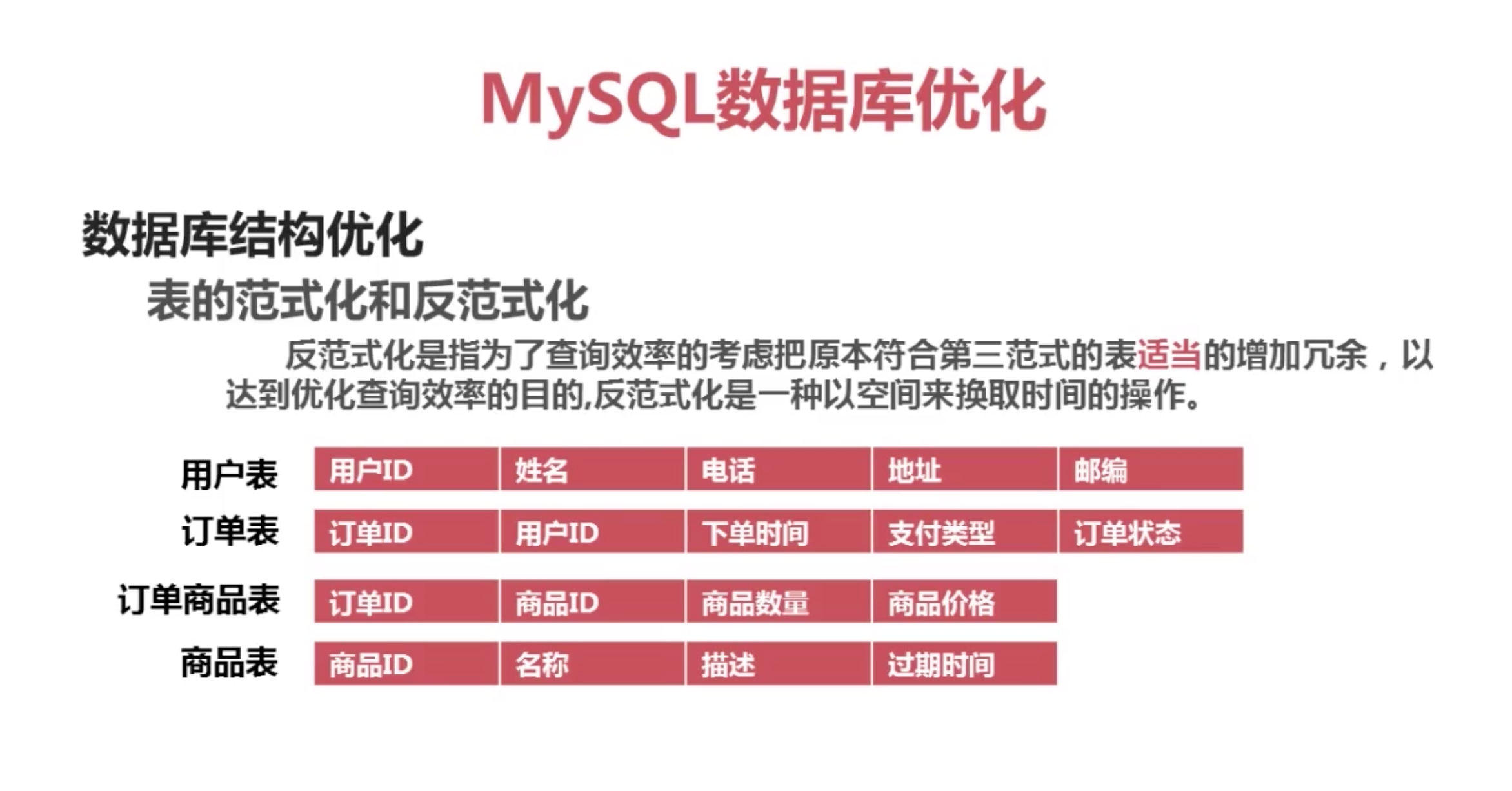
数据库系统配置

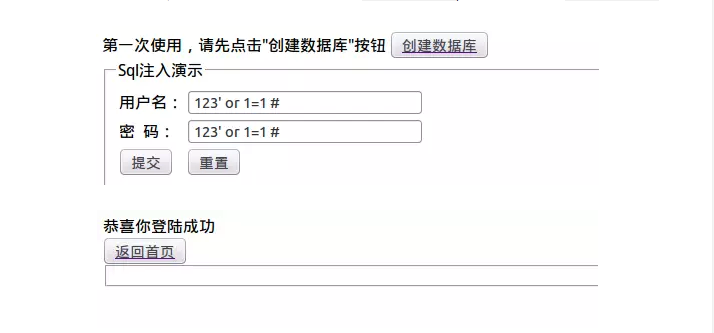
SQL注入
Sql 注入攻击是通过将恶意的 Sql 查询或添加语句插入到应用的输入参数中,再在后台 Sql 服务器上解析执行进行的攻击,它目前黑客对数据库进行攻击的最常用手段之一。
Mysql 中的dual表
简言之,from dual完全是一个可有可无的东西。只是为了方便使用select 语句中喜欢带上from的开发者。
select sysdate() from dual
select sysdate()
Oracle和MySQL中都有一张名称为dual的虚拟表。
select 1 from Table
1是一常量(可以为任意数值),查到的所有行的值都是它,但从效率上来说,1>xxx>*,因为不用查字典表。
- select 1 from table 增加临时列,每行的列值是写在select后的数,这条sql语句中是1
- select count(1) from table 管count(a)的a值如何变化,得出的值总是table表的行数
- select sum(1) from table 计算临时列的和
用途
一般用来当做判断子查询是否成功(即是否有满足条件的时候使用)
比如:
select * from ta where exists (select 1 from ta.id = tb.id)
这个判断就是(select 1 from ta.id = tb.id)这个查询如果有返回值的话表示当前查询满足条件,一般来说就简单话的用select 1 当然也可以用select * ,或者select 任何东东,因为这里仅仅是表明子查询有结果就行了,至于什么结果无所谓。
「真诚赞赏,手留余香」

真诚赞赏,手留余香
使用微信扫描二维码完成支付
