[TOC]
转载地址:https://blog.csdn.net/jack__frost/article/details/71698285
实验表
学生表
| id | name | sex | age |
|---|---|---|---|
| 1 | 小强 | 男 | 8 |
| 2 | 小花 | 女 | 5 |
| 3 | 小名 | 女 | 6 |
| 4 | 小五 | 女 | 6 |
| 5 | 小星 | 男 | 30 |
|---|---|---|---|
学分表
| id | classType | teacher | number | sid |
|---|---|---|---|---|
| 1 | 物理 | 王老师 | 90 | 1 |
| 2 | 数学 | 李老师 | 70 | 2 |
| 3 | 英语 | 黄老师 | 80 | 3 |
| 4 | 体育 | 易老师 | 99 | 4 |
| 5 | 化学 | 科老师 | 50 | 4 |
| 6 | 语文 | 张老师 | 88 | 2 |
| 7 | 地理 | 地老师 | 60 | 6 |
|---|---|---|---|---|
| 8 | 历史 | 历老师 | 65 | 7 |
基本连接方法
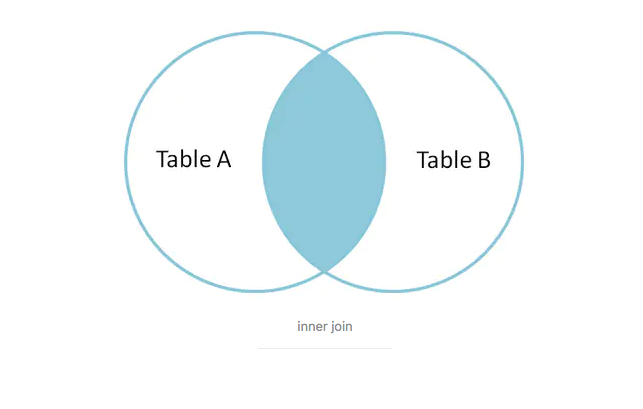
内连接(inner join)
用比较运算符根据每个表共有的列的值匹配两个表中的行(=或>、<)
select * from school.student stu
inner join school.score sco on stu.id = sco.sid
查询数据如下:
| 1 | 小强 | 男 | 8 | 1 | 物理 | 王老师 | 90 | 1 |
|---|---|---|---|---|---|---|---|---|
| 2 | 小花 | 女 | 5 | 2 | 数学 | 李老师 | 70 | 2 |
| 3 | 小名 | 女 | 6 | 3 | 英语 | 黄老师 | 80 | 3 |
| 4 | 小五 | 女 | 6 | 4 | 体育 | 易老师 | 99 | 4 |
| 4 | 小五 | 女 | 6 | 5 | 化学 | 科老师 | 50 | 4 |
| 2 | 小花 | 女 | 5 | 6 | 语文 | 张老师 | 88 | 2 |
很容器看出是两者都满足才查出,7 和 8 没有对应的所以没有出来。
概述
也叫等值连接,得到的满足条件的A和B表内部的数据(必须两边都满足才查出)。如果不添加 ON条件约束的话,取得的是表的笛卡尔积。在添加了ON条件约束后,获取的是同时符合ON条件的 A表和B表数据。
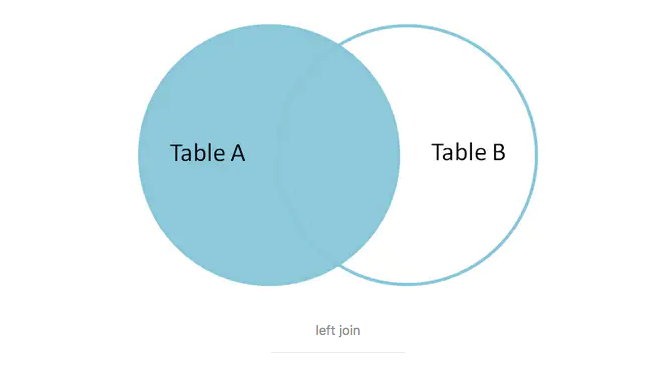
外连接之左连接(left join)
首先是左表数据全部罗列,然后有满足条件的右表数据都会全部罗列出。若两条右表数据对左表一条数据,则会用对应好的左表数据补足作为一条记录。
select * from school.student stu
left join school.score sco on stu.id = sco.sid
查询数据如下:
| 1 | 小强 | 男 | 8 | 1 | 物理 | 王老师 | 90 | 1 |
|---|---|---|---|---|---|---|---|---|
| 2 | 小花 | 女 | 5 | 2 | 数学 | 李老师 | 70 | 2 |
| 3 | 小名 | 女 | 6 | 3 | 英语 | 黄老师 | 80 | 3 |
| 4 | 小五 | 女 | 6 | 4 | 体育 | 易老师 | 99 | 4 |
| 4 | 小五 | 女 | 6 | 5 | 化学 | 科老师 | 50 | 4 |
| 2 | 小花 | 女 | 5 | 6 | 语文 | 张老师 | 88 | 2 |
| 5 | 小星 | 男 | 30 |
概述
以左表为驱动表,取得左表全部的数据。然后右表满足条件的数据会对应在左表数据后面,作为添加的外部行列出。
如果没有满足左表的数据,则会用NULL全部填充到外部行。
如果有多条满足左表数据,那么会用左表对应的数据补足,按行逐条对应右表数据。(也就是左表数据重复生成,右表的每条记录都生成一行,然后对应同一个左表数据)
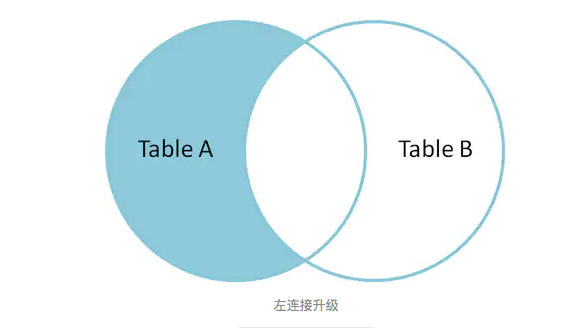
左连接升级(left outer join)
**[left join 或者left outer join(等同于left join)] + [where B.column is null], 查出和两张表中没有关联的数据。
select * from school.student stu
left join school.score sco on stu.id = sco.sid
where sco.sid is null
查询数据如下:
| 5 | 小星 | 男 | 30 | |||||
|---|---|---|---|---|---|---|---|---|
概述
[left join 或者left outer join(等同于left join)] + [where B.column is null] 查询出A表数据,但是排除掉A表和B表的关联数据。 右连接升级同理。同时,也可以把左连接升级和右连接升级的结果 用 union 联合起来,就取到了A和B的消除重复项的集合。
外连接之右连接(right join)
与左连恰恰相反,首先是右表数据全部罗列,然后有满足条件的左表数据都会全部罗列出。若两条左表数据对右表一条数据,则会用对应好的右表数据补足作为一条记录。
select * from school.student stu
right join school.score sco on stu.id = sco.sid
查询数据如下:
| 1 | 小强 | 男 | 8 | 1 | 物理 | 王老师 | 90 | 1 |
|---|---|---|---|---|---|---|---|---|
| 2 | 小花 | 女 | 5 | 2 | 数学 | 李老师 | 70 | 2 |
| 3 | 小名 | 女 | 6 | 3 | 英语 | 黄老师 | 80 | 3 |
| 4 | 小五 | 女 | 6 | 4 | 体育 | 易老师 | 99 | 4 |
| 4 | 小五 | 女 | 6 | 5 | 化学 | 科老师 | 50 | 4 |
| 2 | 小花 | 女 | 5 | 6 | 语文 | 张老师 | 88 | 2 |
| 7 | 地理 | 地老师 | 60 | 6 | ||||
| 8 | 历史 | 历老师 | 65 | 7 |
概述
跟左连接相反,会以右表为驱动表。
右连接升级(right out join)
查出和两张表中没有关联的数据。
select * from school.student stu
right join school.score sco on stu.id = sco.sid
where stu.id is null
查询数据如下:
| 7 | 地理 | 地老师 | 60 | 6 | ||||
|---|---|---|---|---|---|---|---|---|
| 8 | 历史 | 历老师 | 65 | 7 |
概述
跟左外连接相反,会以右表为驱动表。
外连接之全外连接(full [outer] join )
full join (mysql不支持,但是可以用 left join union right join代替)
select * from school.student stu
left join school.score sco on stu.id = sco.sid
union
select * from school.student stu
right join school.score sco on stu.id = sco.sid
查询数据如下:
| 1 | 小强 | 男 | 8 | 1 | 物理 | 王老师 | 90 | 1 |
|---|---|---|---|---|---|---|---|---|
| 2 | 小花 | 女 | 5 | 2 | 数学 | 李老师 | 70 | 2 |
| 3 | 小名 | 女 | 6 | 3 | 英语 | 黄老师 | 80 | 3 |
| 4 | 小五 | 女 | 6 | 4 | 体育 | 易老师 | 99 | 4 |
| 4 | 小五 | 女 | 6 | 5 | 化学 | 科老师 | 50 | 4 |
| 2 | 小花 | 女 | 5 | 6 | 语文 | 张老师 | 88 | 2 |
| 5 | 小星 | 男 | 30 | |||||
| 7 | 地理 | 地老师 | 60 | 6 | ||||
| 8 | 历史 | 历老师 | 65 | 7 |
因为只要满足 union上面的sql或者下面的sql一种情况就ok了。 如下我们可以升级,查询出两种表中没有关系的数据:
select * from school.student stu
left join school.score sco on stu.id = sco.sid
where sco.sid is null
union
select * from school.student stu
right join school.score sco on stu.id = sco.sid
where stu.id is null
查询数据如下:
| 5 | 小星 | 男 | 30 | |||||
|---|---|---|---|---|---|---|---|---|
| 7 | 地理 | 地老师 | 60 | 6 | ||||
| 8 | 历史 | 历老师 | 65 | 7 |
交叉连接(cross join)
交叉联接返回左表中的所有行,左表中的每一行与右表中的所有行组合。
显式的交叉连接:A,B表记录的排列组合,即笛卡儿积。
select * from school.student stu
cross join school.score
order by stu.id
查询数据如下:
| 1 | 小强 | 男 | 8 | 3 | 英语 | 黄老师 | 80 | 3 |
|---|---|---|---|---|---|---|---|---|
| 1 | 小强 | 男 | 8 | 8 | 历史 | 历老师 | 65 | 7 |
| 1 | 小强 | 男 | 8 | 5 | 化学 | 科老师 | 50 | 4 |
| 1 | 小强 | 男 | 8 | 2 | 数学 | 李老师 | 70 | 2 |
| 1 | 小强 | 男 | 8 | 7 | 地理 | 地老师 | 60 | 6 |
| 1 | 小强 | 男 | 8 | 4 | 体育 | 易老师 | 99 | 4 |
| 1 | 小强 | 男 | 8 | 1 | 物理 | 王老师 | 90 | 1 |
| 1 | 小强 | 男 | 8 | 6 | 语文 | 张老师 | 88 | 2 |
| 2 | 小花 | 女 | 5 | 6 | 语文 | 张老师 | 88 | 2 |
| 2 | 小花 | 女 | 5 | 3 | 英语 | 黄老师 | 80 | 3 |
| 2 | 小花 | 女 | 5 | 8 | 历史 | 历老师 | 65 | 7 |
| 2 | 小花 | 女 | 5 | 5 | 化学 | 科老师 | 50 | 4 |
| 2 | 小花 | 女 | 5 | 2 | 数学 | 李老师 | 70 | 2 |
| 2 | 小花 | 女 | 5 | 7 | 地理 | 地老师 | 60 | 6 |
| 2 | 小花 | 女 | 5 | 4 | 体育 | 易老师 | 99 | 4 |
| 2 | 小花 | 女 | 5 | 1 | 物理 | 王老师 | 90 | 1 |
| 3 | 小名 | 女 | 6 | 1 | 物理 | 王老师 | 90 | 1 |
| 3 | 小名 | 女 | 6 | 6 | 语文 | 张老师 | 88 | 2 |
| 3 | 小名 | 女 | 6 | 3 | 英语 | 黄老师 | 80 | 3 |
| 3 | 小名 | 女 | 6 | 8 | 历史 | 历老师 | 65 | 7 |
| 3 | 小名 | 女 | 6 | 5 | 化学 | 科老师 | 50 | 4 |
| 3 | 小名 | 女 | 6 | 2 | 数学 | 李老师 | 70 | 2 |
| 3 | 小名 | 女 | 6 | 7 | 地理 | 地老师 | 60 | 6 |
| 3 | 小名 | 女 | 6 | 4 | 体育 | 易老师 | 99 | 4 |
| 4 | 小五 | 女 | 6 | 4 | 体育 | 易老师 | 99 | 4 |
| 4 | 小五 | 女 | 6 | 1 | 物理 | 王老师 | 90 | 1 |
| 4 | 小五 | 女 | 6 | 6 | 语文 | 张老师 | 88 | 2 |
| 4 | 小五 | 女 | 6 | 3 | 英语 | 黄老师 | 80 | 3 |
| 4 | 小五 | 女 | 6 | 8 | 历史 | 历老师 | 65 | 7 |
| 4 | 小五 | 女 | 6 | 5 | 化学 | 科老师 | 50 | 4 |
| 4 | 小五 | 女 | 6 | 2 | 数学 | 李老师 | 70 | 2 |
| 4 | 小五 | 女 | 6 | 7 | 地理 | 地老师 | 60 | 6 |
| 5 | 小星 | 男 | 30 | 7 | 地理 | 地老师 | 60 | 6 |
| 5 | 小星 | 男 | 30 | 4 | 体育 | 易老师 | 99 | 4 |
| 5 | 小星 | 男 | 30 | 1 | 物理 | 王老师 | 90 | 1 |
| 5 | 小星 | 男 | 30 | 6 | 语文 | 张老师 | 88 | 2 |
| 5 | 小星 | 男 | 30 | 3 | 英语 | 黄老师 | 80 | 3 |
| 5 | 小星 | 男 | 30 | 8 | 历史 | 历老师 | 65 | 7 |
| 5 | 小星 | 男 | 30 | 5 | 化学 | 科老师 | 50 | 4 |
| 5 | 小星 | 男 | 30 | 2 | 数学 | 李老师 | 70 | 2 |
可以看到, 左边的表5条数据, 每一条对应右边的8条数据, 5*8=40条数据。
select * from school.student stu
cross join school.score sc
where stu.id = sc.sid
order by stu.id
转成内连接,查询如下数据:
| 1 | 小强 | 男 | 8 | 1 | 物理 | 王老师 | 90 | 1 |
|---|---|---|---|---|---|---|---|---|
| 2 | 小花 | 女 | 5 | 6 | 语文 | 张老师 | 88 | 2 |
| 2 | 小花 | 女 | 5 | 2 | 数学 | 李老师 | 70 | 2 |
| 3 | 小名 | 女 | 6 | 3 | 英语 | 黄老师 | 80 | 3 |
| 4 | 小五 | 女 | 6 | 4 | 体育 | 易老师 | 99 | 4 |
| 4 | 小五 | 女 | 6 | 5 | 化学 | 科老师 | 50 | 4 |
隐式的交叉连接,没有CROSS JOIN
select * from school.student stu, school.score sc
where stu.id = sc.sid
order by stu.id
和上面的显示交叉结果数据一样。
| 1 | 小强 | 男 | 8 | 1 | 物理 | 王老师 | 90 | 1 |
|---|---|---|---|---|---|---|---|---|
| 2 | 小花 | 女 | 5 | 6 | 语文 | 张老师 | 88 | 2 |
| 2 | 小花 | 女 | 5 | 2 | 数学 | 李老师 | 70 | 2 |
| 3 | 小名 | 女 | 6 | 3 | 英语 | 黄老师 | 80 | 3 |
| 4 | 小五 | 女 | 6 | 4 | 体育 | 易老师 | 99 | 4 |
| 4 | 小五 | 女 | 6 | 5 | 化学 | 科老师 | 50 | 4 |
UNION用法
超大型数据尽可能尽力不要写子查询,使用连接(JOIN)去替换它,使用联合(UNION)来代替手动创建的临时表。
UNION是会把结果排序,union查询,它可以把需要使用临时表的两条或更多的select查询合并的一个查询中(即把两次或多次查询结果合并起来。)。在客户端的查询会话结束的时候,临时表会被自动删除,从而保证数据库整齐、高效。使用union来创建查询的时候,我们只需要用UNION作为关键字把多个select语句连接起来就可以了,要注意的是所有select语句中的字段数目要想同。
要求
两次查询的列数必须一致
推荐
列的类型可以不一样,但推荐查询的每一列,想对应的类型以一样
可以来自多张表的数据
多次sql语句取出的列名可以不一致,此时以第一个sql语句的列名为准。
如果不同的语句中取出的行,有完全相同(这里表示的是每个列的值都相同),那么union会将相同的行合并,最终只保留一行。也可以这样理解,union会去掉重复的行。如果不想去掉重复的行,可以使用union all。
如果子句中有order by,limit,需用括号()包起来。推荐放到所有子句之后,即对最终合并的结果来排序或筛选。
(select * from school.student stu
left join school.score sco on stu.id = sco.sid
limit 0,4)
union
(select * from school.student stu
right join school.score sco on stu.id = sco.sid
limit 0,4 )
这里student的表中只有4条是score表中对应的,所以如此后,就合并成一条了, 查询如下数据:
| 1 | 小强 | 男 | 8 | 1 | 物理 | 王老师 | 90 | 1 |
|---|---|---|---|---|---|---|---|---|
| 2 | 小花 | 女 | 5 | 2 | 数学 | 李老师 | 70 | 2 |
| 3 | 小名 | 女 | 6 | 3 | 英语 | 黄老师 | 80 | 3 |
| 4 | 小五 | 女 | 6 | 4 | 体育 | 易老师 | 99 | 4 |
注意
1、UNION 结果集中的列名总是等于第一个 SELECT 语句中的列名。
2、UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同。
UNION ALL的作用和语法
默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。当 ALL 随 UNION 一起使用时(即 UNION ALL),不消除重复行。
(select * from school.student stu
left join school.score sco on stu.id = sco.sid
limit 0,4)
union ALL
(select * from school.student stu
right join school.score sco on stu.id = sco.sid
limit 0,4)
查询数据如下:
| 1 | 小强 | 男 | 8 | 1 | 物理 | 王老师 | 90 | 1 |
|---|---|---|---|---|---|---|---|---|
| 2 | 小花 | 女 | 5 | 2 | 数学 | 李老师 | 70 | 2 |
| 3 | 小名 | 女 | 6 | 3 | 英语 | 黄老师 | 80 | 3 |
| 4 | 小五 | 女 | 6 | 4 | 体育 | 易老师 | 99 | 4 |
| 1 | 小强 | 男 | 8 | 1 | 物理 | 王老师 | 90 | 1 |
| 2 | 小花 | 女 | 5 | 2 | 数学 | 李老师 | 70 | 2 |
| 3 | 小名 | 女 | 6 | 3 | 英语 | 黄老师 | 80 | 3 |
| 4 | 小五 | 女 | 6 | 4 | 体育 | 易老师 | 99 | 4 |
关于 UNION 和 UNION ALL 的区别
原文链接:https://www.jianshu.com/p/048d93d3ee54
- union 会对联合后的结果集去重,而union all 不会去重,可能取得相同的数据。
- UNION 会按照结果的第一个字段进行默认排序**(重点)。UNION ALL只是简单的取集合。但是相对的 UNION ALL的效率会更高。
- 如果想自定义排序,可以在UNION 结束之后,自定义order by 条件。
「真诚赞赏,手留余香」

真诚赞赏,手留余香
使用微信扫描二维码完成支付
