[TOC]
说明:本文来自于https://www.bilibili.com/video/av64033816/?p=1>视频讲解
转载地址:https://www.cnblogs.com/jingmoxukong/p/8118791.html
官方文档:https://www.elastic.co/guide/en/logstash/current/index.html 版本6.8.3
中文文档:https://www.kancloud.cn/aiyinsi-tan/logstash/849604
简介
Logstash可以动态的将不同来源的数据进行归一并将格式化的数据存储到你选择的位置。对你的所有做数据清洗和大众化处理,踩踏做数据分析和可视化。Logstash 是插件式管理模式,在输入、过滤、输出以及编码过程中都可以使用插件进行定制。Logstash 社区有超过 200 种可用插件。
Logstash 可以传输和处理你的日志、事务或其他数据。
搜集数据—>过滤数据—>处理数据。
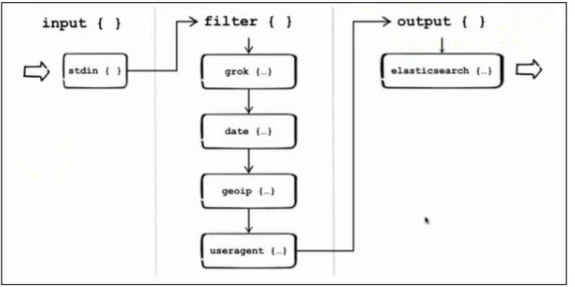
根据提供的不同的插件, 我们可以用来做分析,监控,警报等。
常用用途流程
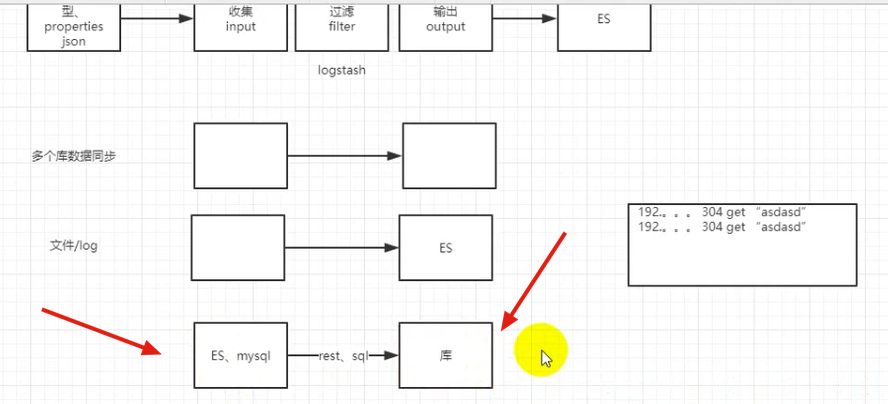
通过从数据库或者文件中,收集好数据, 然后放到了Logstash中对数据进行清洗,这里的清洗包括对数据的过滤,数据的格式化等,最后存入到ES中。
同时如上面的划线地方, 他也可以监控ES,mysql中的sql语句或者是数据的变化, 然后把变化的数据发送到存储库中。
如何处理日志
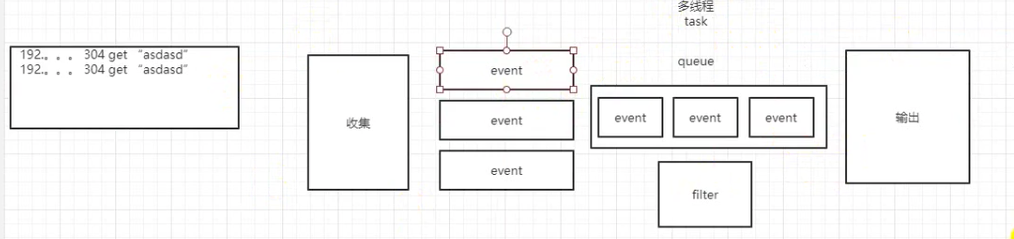
读取每一条日志, 然后产生一个event事件,这个事件放入到队列中,然后在filter中进行过滤,最后输出。 内部是已event来进行处理的。
**在实际应用场景中,通常输入、输出、过滤器不止一个。**Logstash 的这三个元素都使用插件式管理方式,用户可以根据应用需要,灵活的选用各阶段需要的插件,并组合使用。
配置文件理解

pipelines.yml
Logstash 在 6.0 推出了 multiple pipeline 的解决方案,即在一个 logstash 实例中可以同时进行多个独立数据流程的处理工作。如下可以配置两个配置文件获取数据源。
pipeline.id: nginx
path.config: "/usr/share/logstash/config/logstash-nginx.conf"
pipeline.id: Tomcat
path.config: "/usr/share/logstash/config/logstash-Tomcat.conf"
logstash.yml
logstash 的默认启动配置文件。虽然可以通过指定命令行参数的方式,来控制 logstash 的运行方式,但显然这么做很麻烦。建议通过指定配置文件的方式,来控制 logstash 运行,启动命令如下:
bin/logstash -f logstash.conf
我在搭建环境的时候,直接把里面的都给屏蔽掉了。
logstash.conf
# input{
# file{
# path => ["/rmc.log"]
# start_position => beginning
# sincedb_path => "/dev/null"
# }
# }
input{
tcp {
port => "6666"
mode => "server"
}
}
output {
elasticsearch {
hosts => ["http://192.168.1.100:9200"]
id => "my_plugin_id"
index => "viewdata-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "changeme"
}
stdout {
codec => rubydebug
}
}
#nc 192.168.1.100 6666 < /var/log/nginx/access.log
如此,在另一台机子上不需要搭建Logstash, 用脚本就好了,持续收集数据。
同时很多日志框架可以通过TCP和UDP进行通信处理。
input
Logstash 支持各种输入选择 ,可以在同一时间从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
常用 input 插件
file
从文件系统上的文件读取,就像UNIX命令 tail -0F 一样
syslog
在众所周知的端口514上侦听系统日志消息,并根据RFC3164格式进行解析
redis
从redis服务器读取,使用redis通道和redis列表。 Redis经常用作集中式Logstash安装中的“代理”,它将来自远程Logstash“托运人”的Logstash事件排队。
beats
处理由Filebeat发送的事件。
filter
过滤器是Logstash管道中的中间处理设备。如果符合特定条件,您可以将条件过滤器组合在一起,对事件执行操作。
常用 filter 插件
grok
解析和结构任意文本。 Grok目前是Logstash中将非结构化日志数据解析为结构化和可查询的最佳方法。
mutate
对事件字段执行一般转换。您可以重命名,删除,替换和修改事件中的字段。
drop
完全放弃一个事件,例如调试事件。
clone
制作一个事件的副本,可能会添加或删除字段。
geoip
添加有关IP地址的地理位置的信息(也可以在Kibana中显示惊人的图表!)
output
输出是Logstash管道的最后阶段。一个事件可以通过多个输出,但是一旦所有输出处理完成,事件就完成了执行。
elasticsearch
将事件数据发送给 Elasticsearch(推荐模式)。
file
将事件数据写入文件或磁盘。
graphite
将事件数据发送给 graphite(一个流行的开源工具,存储和绘制指标。 http://graphite.readthedocs.io/en/latest/)。
statsd
将事件数据发送到 statsd (这是一种侦听统计数据的服务,如计数器和定时器,通过UDP发送并将聚合发送到一个或多个可插入的后端服务)。
注意
编写配置文件的时候, 一定要注意里面的格式或者空格, 不然运行错误。 多个插件配置按顺序执行。
对于我们的一些日志框架, 可以通过TCP和UDP来进行采集处理。
jvm.options
logstash 的 JVM 配置文件。
startup.options (Linux)
包含系统安装脚本在 /usr/share/logstash/bin 中使用的选项为您的系统构建适当的启动脚本。安装 Logstash 软件包时,系统安装脚本将在安装过程结束时执行,并使用 startup.options 中指定的设置来设置用户,组,服务名称和服务描述等选项。
Filebeat
他是安装在服务器上面的, 所以可以收集任何机子上的日志文件, mysql的,redis的等都可以。 比如收集查询慢的SQL语句等。
sudo yum install filebeat
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.3.2-linux-x86_64.tar.gz
tar xzvf filebeat-7.3.2-linux-x86_64.tar.gz
后台启动
nohup ./filebeat -e > filebeat.log &
停止
ps -ef |grep filebeat
kill -9 进程号
filebeat.yml
配置Nginx,把nginx日志中的access.log上传到logstash中
#=========================== Filebeat inputs =============================
filebeat.inputs:
- type: log
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /var/log/nginx/access.log
#- c:\programdata\elasticsearch\logs\*
#============================= Filebeat modules ===============================
filebeat.config.modules:
# Glob pattern for configuration loading
path: ${path.config}/modules.d/*.yml
# Set to true to enable config reloading
reload.enabled: false
# Period on which files under path should be checked for changes
#reload.period: 10s
#==================== Elasticsearch template setting ==========================
setup.template.settings:
index.number_of_shards: 1
#index.codec: best_compression
#_source.enabled: false
#============================== Kibana =====================================
# Starting with Beats version 6.0.0, the dashboards are loaded via the Kibana API.
# This requires a Kibana endpoint configuration.
setup.kibana:
#----------------------------- Logstash output --------------------------------
output.logstash:
hosts: ["192.168.1.100:5044"]
#================================ Processors =====================================
# Configure processors to enhance or manipulate events generated by the beat.
processors:
- add_host_metadata: ~
- add_cloud_metadata: ~
「真诚赞赏,手留余香」

真诚赞赏,手留余香
使用微信扫描二维码完成支付
