[TOC]
什么是原子性
原子操作是不可分割的。(我们要站在多线程的角度)指访问某个共享变量的操作从其执行线程之外的线程来看,该操作要么已经执行完毕,要么尚未发生,其他线程不会看到执行操作的中间结果。
比如: AtomicBoolean是Java.util.concurrent.atomic包下的原子变量,这个包里面提供了一组原子类。其基本的特性就是在多线程环境下,当有多个线程同时执行这些类的实例包含的方法时,具有排他性,即当某个线程进入方法,执行其中的指令时,不会被其他线程打断,而别的线程就像自旋锁一样,一直等到该方法执行完成,才由JVM从等待队列中选择一个另一个线程进入,这只是一种逻辑上的理解。实际上是借助硬件的相关指令来实现的,不会阻塞线程(或者说只是在硬件级别上阻塞了)。
CAS算法
转载地址:https://www.cnblogs.com/qjjazry/p/6581568.html
乐观锁与悲观锁和CAS
悲观锁:总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。再比如Java里面的同步原语synchronized关键字的实现也是悲观锁。
乐观锁:顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁。在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的。
乐观锁的一种实现方式-CAS
锁存在的问题
Java在JDK1.5之前都是靠 synchronized关键字保证同步的,这种通过使用一致的锁定协议来协调对共享状态的访问,可以确保无论哪个线程持有共享变量的锁,都采用独占的方式来访问这些变量。这就是一种独占锁,独占锁其实就是一种悲观锁,所以可以说 synchronized 是悲观锁。
悲观锁机制存在以下问题
-
在多线程竞争下,加锁、释放锁会导致比较多的上下文切换和调度延时,引起性能问题。
-
一个线程持有锁会导致其它所有需要此锁的线程挂起。
-
如果一个优先级高的线程等待一个优先级低的线程释放锁会导致优先级倒置,引起性能风险。
对比于悲观锁的这些问题,另一个更加有效的锁就是乐观锁。其实乐观锁就是:每次不加锁而是假设没有并发冲突而去完成某项操作,如果因为并发冲突失败就重试,直到成功为止。
CAS
CAS是乐观锁技术,当多个线程尝试使用CAS同时更新同一个变量时,只有其中一个线程能更新变量的值,而其它线程都失败,失败的线程并不会被挂起,而是被告知这次竞争中失败,并可以再次尝试。
**CAS 操作中包含三个操作数 —— 需要读写的内存位置(V)、进行比较的预期原值(A)和拟写入的新值(B)。如果内存位置V的值与预期原值A相匹配,那么处理器会自动将该位置值更新为新值B。否则处理器不做任何操作。**无论哪种情况,它都会在 CAS 指令之前返回该位置的值。(在 CAS 的一些特殊情况下将仅返回 CAS 是否成功,而不提取当前值。)CAS 有效地说明了“ 我认为位置 V 应该包含值 A;如果包含该值,则将 B 放到这个位置;否则,不要更改该位置,只告诉我这个位置现在的值即可。 ”这其实和乐观锁的冲突检查+数据更新的原理是一样的。
AtomicInteger 源码查看
public class AtomicInteger extends Number implements java.io.Serializable {
private volatile int value;
public final int get() {
return value;
}
public final int getAndIncrement() {
for (;;) {
int current = get();
int next = current + 1;
if (compareAndSet(current, next))
return current;
}
}
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
}
在没有锁的机制下,字段value要借助volatile原语,保证线程间的数据是可见性。这样在获取变量的值的时候才能直接读取。然后来看看 ++i 是怎么做到的。
getAndIncrement 采用了CAS操作,每次从内存中读取数据然后将此数据和 +1 后的结果进行CAS操作,如果成功就返回结果,否则重试直到成功为止。
什么是ABA问题
原文链接:https://blog.csdn.net/q5706503/article/details/84558343
如果内存地址V初次读取的值是A,并且在准备赋值的时候检查到它的值仍然为A,那我们就能说它的值没有被其他线程改变过了吗?
如果在这段期间它的值曾经被改成了B,后来又被改回为A,那CAS操作就会误认为它从来没有被改变过。这个漏洞称为CAS操作的“ABA”问题。Java并发包为了解决这个问题,提供了一个带有标记的原子引用类“AtomicStampedReference”,它可以通过控制变量值的版本来保证CAS的正确性。因此,在使用CAS前要考虑清楚“ABA”问题是否会影响程序并发的正确性,如果需要解决ABA问题,改用传统的互斥同步可能会比原子类更高效。
CAS与Synchronized的使用情景
1、对于资源竞争较少(线程冲突较轻)的情况,使用synchronized同步锁进行线程阻塞和唤醒切换以及用户态内核态间的切换操作额外浪费消耗cpu资源;而CAS基于硬件实现,不需要进入内核,不需要切换线程,操作自旋几率较少,因此可以获得更高的性能。
2、对于资源竞争严重(线程冲突严重)的情况,CAS自旋的概率会比较大,从而浪费更多的CPU资源,效率低于synchronized。
补充: synchronized在jdk1.6之后,已经改进优化。synchronized的底层实现主要依靠Lock-Free的队列,基本思路是自旋后阻塞,竞争切换后继续竞争锁,稍微牺牲了公平性,但获得了高吞吐量。在线程冲突较少的情况下,可以获得和CAS类似的性能;而线程冲突严重的情况下,性能远高于CAS。
CAS缺点和优点
循环时间长开销很大
我们可以看到getAndAddInt方法执行时,如果CAS失败,会一直进行尝试。如果CAS长时间一直不成功,可能会给CPU带来很大的开销。
只能保证一个共享变量的原子操作
当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候就可以用锁来保证原子性。通过AtomicStampedReference这个类可以解决。
ABA问题
unsafe
链接:https://www.jianshu.com/p/0af96190d554
原文链接:https://blog.csdn.net/alex_xfboy/article/details/85101402
Java是一种安全的编程语言,可以防止程序员犯许多愚蠢的错误,其中大多数错误都是基于内存管理的。但是,有一种方法可以绕过这些限制,即使用 Unsafe class。可以手动操作内存,这样可以大大减少垃圾回收时间而且可以减少堆内内存的使用。
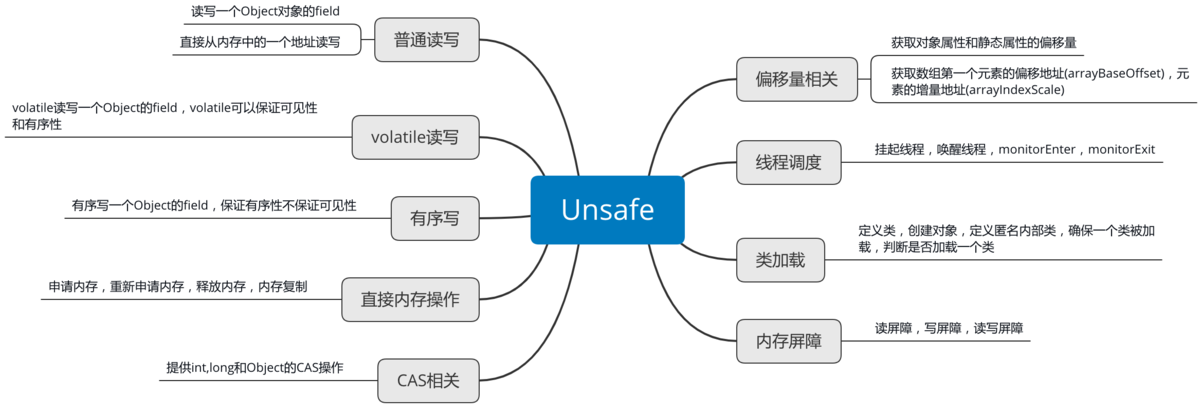
体验过多线程程序开发之后,可能问自己一个问题,Java 内置的锁是如何实现的?最常用的最简单的锁要数ReentrantLock,那线程是如何实现阻塞自己的?
线程阻塞原语,底层实现是通过 Unsafe 类的 park(阻塞) 和 unpark (唤醒)方法做到的。但这两个方法都是 native 方法,它们本身是由 C 语言来实现的核心功能。
Java.util.concurrent.atomic包
转载链接:https://blog.csdn.net/weixin_42146366/article/details/87818560
Java.util.concurrent.atomic包下的原子变量,这个包里面提供了一组原子类。其基本的特性就是在多线程环境下,当有多个线程同时执行这些类的实例包含的方法时,具有排他性,即当某个线程进入方法,执行其中的指令时,不会被其他线程打断,而别的线程就像自旋锁一样,一直等到该方法执行完成,才由JVM从等待队列中选择一个另一个线程进入,这只是一种逻辑上的理解。实际上是借助硬件的相关指令来实现的,不会阻塞线程(或者说只是在硬件级别上阻塞了)。
基本类型
AtomicInteger
常用方法API
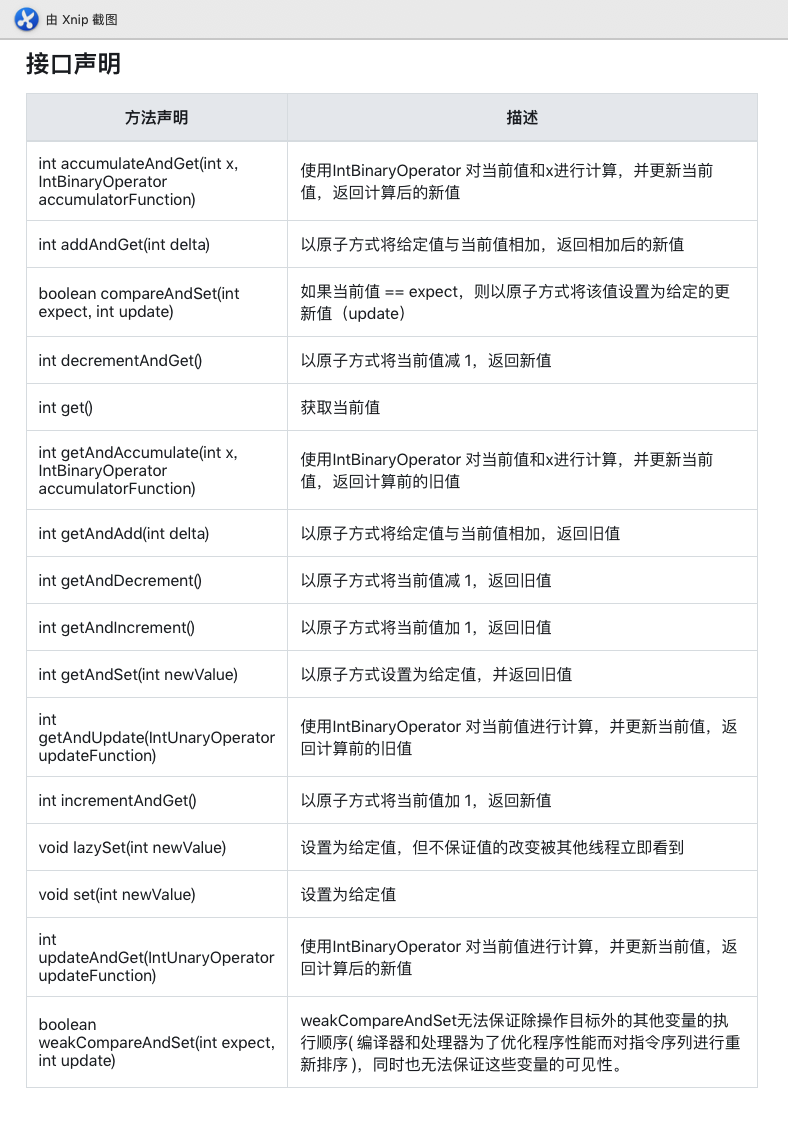
代码演示
import java.util.concurrent.atomic.AtomicInteger;
public class AtomicIntegerTest {
public static void main(String[] args) {
AtomicInteger count = new AtomicInteger(10);
// 以原子方式将给定值与当前值相加,返回相加后的新值
count.addAndGet(2);
System.out.println(count.get());
// 以原子方式将当前值减 1,返回新值
count.decrementAndGet();
System.out.println(count.get());
// 以原子方式将当前值加 1,返回新值
count.incrementAndGet();
System.out.println(count.get());
// 如果当前值 == expect,则以原子方式将该值设置为给定的更新值(update)
count.compareAndSet(11, 100);
System.out.println(count.get());
// 以原子方式将给定值与当前值相加,返回旧值
int currentCount = count.getAndAdd(10);
System.out.println(currentCount + "---" + count.get());
// 以原子方式将当前值减 1,返回旧值
currentCount = count.getAndDecrement();
System.out.println(currentCount + "---" + count.get());
// 以原子方式将当前值加 1,返回旧值
currentCount = count.getAndIncrement();
System.out.println(currentCount + "---" + count.get());
// 以原子方式设置为给定值,并返回旧值
currentCount = count.getAndSet(10);
System.out.println(currentCount + "---" + count.get());
count.set(1000);
System.out.println(count.get());
}
}
运行结果
12
11
12
12
12---22
22---21
21---22
22---10
1000
AtomicInteger源码部分讲解
public class AtomicInteger extends Number implements java.io.Serializable {
private static final long serialVersionUID = 6214790243416807050L;
// setup to use Unsafe.compareAndSwapInt for updates
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
private volatile int value;
以上为AtomicInteger中的部分源码,在这里说下其中的value,这里value使用了volatile关键字,volatile在这里可以做到的作用是使得多个线程可以共享变量,但是问题在于使用volatile将使得VM优化失去作用,导致效率较低,所以要在必要的时候使用,因此AtomicInteger类不要随意使用,要在使用场景下使用。
AtomicLong
常用API方法和AtomicInteger一致。
AtomicBoolean
转载地址:https://blog.csdn.net/xiaoguangtouqiang/article/details/81319093
常用API方法和AtomicInteger一致。
public class AtomicBooleanTest implements Runnable {
private static AtomicBoolean exists = new AtomicBoolean(false);
private String name;
public AtomicBooleanTest(String name) {
this.name = name;
}
@Override
public void run() {
if(exists.compareAndSet(false, true)) {
System.out.println(name + ":enter");
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(name + ":leave");
exists.set(false);
}else{
System.out.println(name +":give up");
}
}
public static void main(String[] args) throws InterruptedException {
AtomicBooleanTest bar1 = new AtomicBooleanTest("bar1");
AtomicBooleanTest bar2 = new AtomicBooleanTest("bar2");
new Thread(bar1).start();
new Thread(bar2).start();
}
以上可以看到, 如果
exists.compareAndSet(false, true)
在处理这个方法的时候, 另外一条线程需要等待他处理完成后, 才能进行其他的判断,也就是在这个地方等待中。
数组类型
AtomicIntegerArray
AtomicIntegerArray提供的功能:整型数组的元素支持原子性更新操作。 常用的API的操作和AtomicInteger的差不多。
AtomicLongArray
同上。
AtomicReferenceArray
引用类型
AtomicReference
原文链接:https://blog.csdn.net/weixin_42146366/article/details/87822781
①.AtomicReference和AtomicInteger非常类似,不同之处就在于AtomicInteger是对整数的封装,而AtomicReference则对应普通的对象引用。也就是它可以保证你在修改对象引用时的线程安全性。
②.AtomicReference是作用是对”对象”进行原子操作。 提供了一种读和写都是原子性的对象引用变量。原子意味着多个线程试图改变同一个AtomicReference(例如比较和交换操作)将不会使得AtomicReference处于不一致的状态。
使用场景
转载地址: https://segmentfault.com/a/1190000015831791?utm_source=tag-newest
AtomicReference提供了以无锁方式访问共享资源的能力,看看如何通过AtomicReference保证线程安全,来看个具体的例子
public class AtomicRefTest {
public static void main(String[] args) throws InterruptedException {
AtomicReference<Integer> ref = new AtomicReference<>(new Integer(1000));
List<Thread> list = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
Thread t = new Thread(new Task(ref), "Thread-" + i);
list.add(t);
t.start();
}
for (Thread t : list) {
t.join();
}
System.out.println(ref.get()); // 打印2000
}
}
class Task implements Runnable {
private AtomicReference<Integer> ref;
Task(AtomicReference<Integer> ref) {
this.ref = ref;
}
@Override
public void run() {
for (;;) { // 自旋操作
Integer oldV = ref.get();
if (ref.compareAndSet(oldV, oldV + 1)) // CAS操作
break;
}
}
}
运行结果是2000.
通过示例,可以总结出AtomicReference的一般使用模式如下:
AtomicReference<Object> ref = new AtomicReference<>(new Object());
Object oldCache = ref.get();
// 对缓存oldCache做一些操作
Object newCache = someFunctionOfOld(oldCache);
// 如果期间没有其它线程改变了缓存值,则更新
boolean success = ref.compareAndSet(oldCache , newCache);
AtomicStampedReference
和AtomicReference相比,AtomicStampedReference中的每个引用变量都带上了pair.stamp这个版本号,这样就可以解决CAS中的ABA问题了。
AtomicMarkableReference
AtomicStampedReference可以给引用加上版本号,追踪引用的整个变化过程,如: A -> B -> C -> D - > A,通过AtomicStampedReference,我们可以知道,引用变量中途被更改了3次。但是,有时候,我们并不关心引用变量更改了几次,只是单纯的关心是否更改过,所以就有了AtomicMarkableReference
对象的属性修改类型
AtomicIntegerFieldUpdater, AtomicLongFieldUpdater, AtomicReferenceFieldUpdater 。
「真诚赞赏,手留余香」

真诚赞赏,手留余香
使用微信扫描二维码完成支付
