[TOC]
说明:本文来自于https://www.bilibili.com/video/av64033816/?p=1>视频讲解
官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/6.0/getting-started.html 对应版本:6.8.3
创建/修改文档
格式
他会自动判断是插入还是修改
PUT or POST /{index}/{type}/{id}
{
"":""
}
一般用POST,没有id他回自动生成一个UUID
创建
POST teacher/student/3
{
"name": "麦子",
"age": 18
}
{
"_index" : "teacher",
"_type" : "student",
"_id" : "3",
"_version" : 1,
"result" : "created",#创建返回结果
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
{
"_index" : "teacher",
"_type" : "student",
"_id" : "2",
"_version" : 4, #通过版本号的变化来进行乐观锁的处理。
"result" : "updated",#修改返回结果
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1
}
批量插入
POST maizi_index/data/_bulk #注意这个关键字
{"index":{"_id":1}}
{"username":"java","age":10,"sex":"男"}
{"index":{"_id":2}}
{"username":"ios","age":10,"sex":"男"}
{"index":{"_id":3}}
{"username":"andrid","age":2,"sex":"女"}
{"index":{"_id":4}}
{"username":"go","age":4,"sex":"女"}
查找文档
查询写的时候可以省略{type}这个字段
基本查找
#查
GET my_inde/doc/1
#全部查询
GET my_inde/doc/_search
#全文检索 , 只要某一个字段包含就可以查询出来
GET my_inde/doc/_search?q=180
#模糊检索 , 只要某一个字段包含就可以查询出来
GET my_inde/doc/_search?q=yb
#返回某一些字段 _source
GET teacher/student/_search?q=ball&_source=play,xx,xx
多个查询
#查找多个文档
GET maizi_index/data/_mget
{
"ids":[1,2]
}
#查询所有索引
GET _search
#在多个索引中查询
GET /maizi_index,maizi/_search
#通配符查询
GET /maizi_*/_search
常用查询
#指定字段查询,相当于 where username=java
GET maizi_index/_search?q=username:php
GET maizi_index/_search?q=java&df=username
#排序
GET maizi_index/_search?sort=age:desc
#分页
GET maizi_index/_search?sort=age:desc&from=2&size=2
#超时
GET maizi_index/_search?timeout=1s
#term
GET maizi_index/_search?q=java js php 这个相当于 or
#phrase
GET maizi_index/_search?q="java js php" 这个相当于查询 "java js php"整体,没有分词
#查询优先级, 用括号处理, 其中AND 和 OR 一定要大写
GET maizi_index/_search?q=username:(java AND php) OR js
#多字段查询
GET maizi_index/_search?q=username:(java OR php) AND age:11 AND _id:2
#查看执行计划
GET maizi_index/_search?q=username:(java OR php)
{
"profile": "true"
}
#操作符 NOT, 包含java,一定不包含php
GET maizi_index/_search?q=username:(java NOT php)
#操作符 +,-,包含java,一定不包含php
GET maizi_index/_search?q=username:(+java -php)
#范围查询
#[10 TO 20] 10<=age<=20
GET maizi_index/_search?q=age:(>10)
GET maizi_index/_search?q=age:(>=10 AND <11)
#通配符查询 效率低, 不建议使用
# ?是一个字符匹配 *是多个
GET maizi_index/_search?q=username:jav?
#正则匹配
GET maizi_index/_search?q=username:/[jb]ave/
Request Search 写法
感觉下面这种方式更加清晰。
#查询,分页,返回指定字段,排序
GET maizi_index/_search
{
"query": {
"match_all": {
}
},
"_source": ["age","username"],
"from": 0,
"size": 2,
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
#字段匹配
GET maizi_index/_search
{
"query": {
"match": {
"username":{
"query": "java js php",
"operator": "and"
}
}
}
}
#词语匹配
GET maizi_index/_search
{
"query": {
"match_phrase": {
"username": "java js php"
}
}
}
#slop 表示可以有几个词语的差异
GET maizi_index/_search
{
"query": {
"match_phrase": {
"username": {
"query": "java php",
"slop": 1
}
}
}
}
#可以完成多字段字符查询
GET maizi_index/_search
{
"query": {
"query_string": {
"default_field": "username",
"query": "java AND php"
}
}
}
#两个字段去匹配
GET maizi_index/_search
{
"query": {
"query_string": {
"fields": ["username","sex"],
"query": "ios or php"
}
}
}
#不分词查询
GET maizi_index/_search
{
"query": {
"term": {
"username": {
"value": "java"
}
}
}
}
GET maizi_index/_search
{
"query": {
"terms": {
"username": [
"andrid",
"php"
]
}
}
}
#范围查询
GET maizi_index/_search
{
"query": {
"range": {
"age": {
"gte": 10,
"lte": 20
}
}
}
}
Bool Query
后期补上
删除文档
#删除单个文档
DELETE maizi_index/data/1
#删除index
DELETE /maizi_index
Mapping
作用
定义数据库中的表的结构的定义,通过mapping来控制索引存储数据库的设置
a. 定义index下的字段名
b. 定义字段的类型,比如数值类型/字符串/布尔等
c. 定义倒排索引相关的配置,比如documentId,记录position,打分等。
获取索引Mapping
不进行配置的时候,自动创建mapping
#查看所有字段索引
GET maizi_index/_mapping
#查看具体一个字段索引
GET maizi_index/_mapping/field/sex
自定义Mapping
PUT yb_index
{
"mappings": {
"_doc": {
"dynamic": false,
"properties": {
"title": {
"type": "text"
},
"name": {
"type": "text"
},
"age": {
"type": "integer"
},
"created": {
"type": "date",
"format": "strict_date_optional_time||epoch_millis"
}
}
}
}
}
该dynamic设置控制是否可以动态添加新字段。它接受三种设置:
| 参数 | 说明 |
|---|---|
| true | 允许自动新增字段(默认) |
| false | 不允许自动新增字段,但是文档可以正常写入,无法对字段进行查询操作 |
| strict | 文档不能写入(如果写入就回报错) |
相关性算分
指文档与查询语句间的相关度,通过倒排索引可以获取与查询语句相匹配的文档列表。
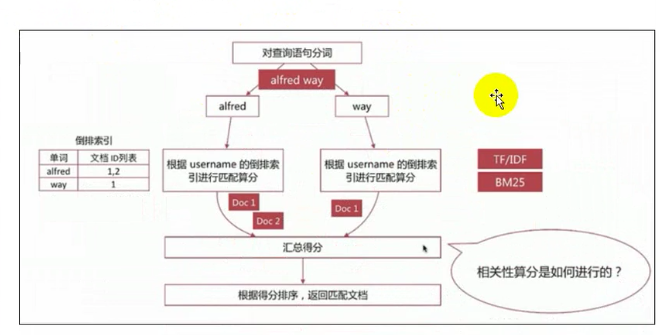
如何将符合用户查询需求的文档列表放到前面?
本质问题是一个排序问题, 排序的依据是相关性算分,确定倒排索引哪个文档在前面。
影响相关性算分的参数
TF(Term Frequency)
词频,单词在文档中出现的次数,词频越高,相关度越高。
Document Frequency(DF)
文档词频,就是单词出现的文档数。
IDF
逆向文档词频,与文档词频相反,即单词出现的文档数越少,相关度越高。(如果一个单词在文档集出现越少,算为越重要单词)
Field-length norm
文档越短,相关度越高。
「真诚赞赏,手留余香」

真诚赞赏,手留余香
使用微信扫描二维码完成支付
