[TOC]
说明:以下文字来源网络各相关面试题目收集
List 和 Set 的区别
List , Set 都是继承自 Collection 接口 List 特点:元素有放入顺序,元素可重复 ,
Set 特点:元素无放入顺序,元素不可重复,重复元素会覆盖掉,(元素虽然无放入顺序,但是元素在set中的位 置是有该元素的 HashCode 决定的,其位置其实是固定的,加入Set 的 Object 必须定义 equals ()方法 ,另外list 支持for循环,也就是通过下标来遍历,也可以用迭代器,但是set只能用迭代,因为他无序,无法用下标来取得想 要的值。) Set和List
对比 Set:检索元素效率低下,删除和插入效率高,插入和删除不会引起元素位置改变。 List:和数组类似,List可以动态增长,查找元素效率高,插入删除元素效率低,因为会引起其他元素位置改变
HashSet 是如何保证不重复的
向 HashSet 中 add ()元素时,判断元素是否存在的依据,不仅要比较hash值,同时还要结合 equles 方法比较。 HashSet 中的 add ()方法会使用 HashMap 的 add ()方法。以下是 HashSet 部分源码:
private static final Object PRESENT = new Object();
private transient HashMap<E,Object> map;
public HashSet()
{
map = new HashMap<>();
}
public boolean add(E e)
{
return map.put(e, PRESENT)==null;
}
HashMap 的 key 是唯一的,由上面的代码可以看出 HashSet 添加进去的值就是作为 HashMap 的key。所以不会 重复( HashMap 比较key是否相等是先比较 hashcode 在比较 equals )。
HashMap 是线程安全的吗,为什么不是线程安全的?
不是线程安全的;
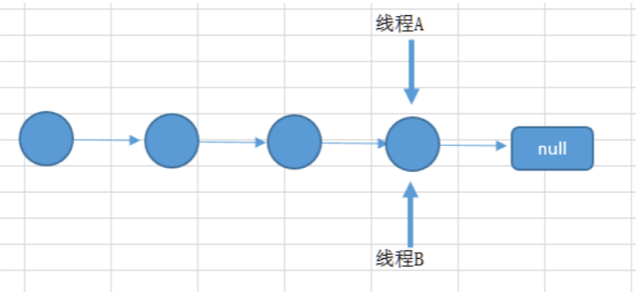
如果有两个线程A和B,都进行插入数据,刚好这两条不同的数据经过哈希计算后得到的哈希码是一样的,且该位 置还没有其他的数据。所以这两个线程都会进入我在上面标记为1的代码中。假设一种情况,线程A通过if判断,该 位置没有哈希冲突,进入了if语句,还没有进行数据插入,这时候 CPU 就把资源让给了线程B,线程A停在了if语句 里面,线程B判断该位置没有哈希冲突(线程A的数据还没插入),也进入了if语句,线程B执行完后,轮到线程A执 行,现在线程A直接在该位置插入而不用再判断。这时候,你会发现线程A把线程B插入的数据给覆盖了。发生了线 程不安全情况。本来在 HashMap 中,发生哈希冲突是可以用链表法或者红黑树来解决的,但是在多线程中,可能 就直接给覆盖了。
上面所说的是一个图来解释可能更加直观。如下面所示,两个线程在同一个位置添加数据,后面添加的数据就覆盖 住了前面添加的。

如果上述插入是插入到链表上,如两个线程都在遍历到最后一个节点,都要在最后添加一个数据,那么后面添加数 据的线程就会把前面添加的数据给覆盖住。则
在扩容的时候也可能会导致数据不一致,因为扩容是从一个数组拷贝到另外一个数组。
HashMap 的扩容过程
当向容器添加元素的时候,会判断当前容器的元素个数,如果大于等于阈值(知道这个阈字怎么念吗?不念 fa 值, 念 yu 值四声)—即当前数组的长度乘以加载因子的值的时候,就要自动扩容啦。
扩容( resize )就是重新计算容量,向 HashMap 对象里不停的添加元素,而 HashMap 对象内部的数组无法装载更 多的元素时,对象就需要扩大数组的长度,以便能装入更多的元素。当然 Java 里的数组是无法自动扩容的,方法 是使用一个新的数组代替已有的容量小的数组,就像我们用一个小桶装水,如果想装更多的水,就得换大水桶。
HashMap hashMap=new HashMap(cap);
cap =3, hashMap 的容量为4;
cap =4, hashMap 的容量为4;
cap =5, hashMap 的容量为8;
cap =9, hashMap 的容量为16;
如果 cap 是2的n次方,则容量为 cap ,否则为大于 cap 的第一个2的n次方的数。
HashMap 1.7 与 1.8 的 区别,说明 1.8 做了哪些优化,如何优化的?
HashMap结构图
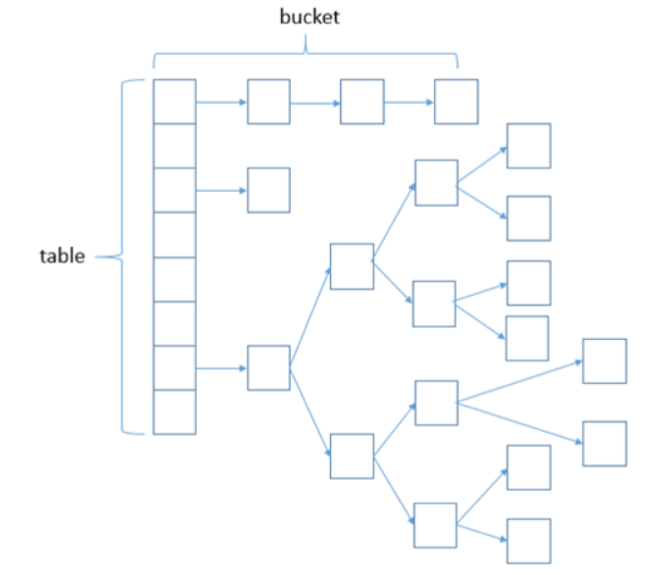
在 JDK1.7 及之前的版本中, HashMap 又叫散列链表:基于一个数组以及多个链表的实现,hash值冲突的时候, 就将对应节点以链表的形式存储。
JDK1.8 中,当同一个hash值( Table 上元素)的链表节点数不小于8时,将不再以单链表的形式存储了,会被 调整成一颗红黑树。这就是 JDK7 与 JDK8 中 HashMap 实现的最大区别。
其下基于 JDK1.7.0_80 与 JDK1.8.0_66 做的分析
JDK1.7中
使用一个 Entry 数组来存储数据,用key的 hashcode 取模来决定key会被放到数组里的位置,如果 hashcode 相 同,或者 hashcode 取模后的结果相同( hash collision ),那么这些 key 会被定位到 Entry 数组的同一个 格子里,这些 key 会形成一个链表。
在 hashcode 特别差的情况下,比方说所有key的 hashcode 都相同,这个链表可能会很长,那么 put/get 操作 都可能需要遍历这个链表,也就是说时间复杂度在最差情况下会退化到 O(n)
JDK1.8中
使用一个 Node 数组来存储数据,但这个 Node 可能是链表结构,也可能是红黑树结构
-
如果插入的 key 的 hashcode 相同,那么这些key也会被定位到 Node 数组的同一个格子里。
-
如果同一个格子里的key不超过8个,使用链表结构存储。
-
如果超过了8个,那么会调用 treeifyBin 函数,将链表转换为红黑树。
那么即使 hashcode 完全相同,由于红黑树的特点,查找某个特定元素,也只需要O(log n)的开销
也就是说put/get的操作的时间复杂度最差只有 O(log n) 听起来挺不错,但是真正想要利用 JDK1.8 的好处,有一个限制:
key的对象,必须正确的实现了 Compare 接口
如果没有实现 Compare 接口,或者实现得不正确(比方说所有 Compare 方法都返回0)
那 JDK1.8 的 HashMap 其实还是慢于 JDK1.7 的
简单的测试数据如下:
向 HashMap 中 put/get 1w 条 hashcode 相同的对象
JDK1.7: put 0.26s , get 0.55s
JDK1.8 (未实现 Compare 接口): put 0.92s , get 2.1s
但是如果正确的实现了 Compare 接口,那么 JDK1.8 中的 HashMap 的性能有巨大提升,这次 put/get 100W条 hashcode 相同的对象
JDK1.8 (正确实现 Compare 接口,): put/get 大概开销都在320 ms 左右
Java反射机制
Java 反射机制是在运行状态中,对于任意一个类,都能够获得这个类的所有属性和方法,对于任意一个对象都能够 调用它的任意一个属性和方法。这种在运行时动态的获取信息以及动态调用对象的方法的功能称为 Java 的反射机 制。
Class 类与 java.lang.reflect 类库一起对反射的概念进行了支持,该类库包含了 Field,Method,Constructor 类 (每 个类都实现了 Member 接口)。这些类型的对象时由 JVM 在运行时创建的,用以表示未知类里对应的成员。
这样你就可以使用 Constructor 创建新的对象,用 get() 和 set() 方法读取和修改与 Field 对象关联的字段,用 invoke() 方法调用与 Method 对象关联的方法。另外,还可以调用 getFields() getMethods() 和 getConstructors() 等很便利的方法,以返回表示字段,方法,以及构造器的对象的数组。这样匿名对象的信息 就能在运行时被完全确定下来,而在编译时不需要知道任何事情。
LinkedHashMap 的应用
基于 LinkedHashMap 的访问顺序的特点,可构造一个 LRU(Least Recently Used) 最近最少使用简单缓存。 也有一些开源的缓存产品如 ehcache 的淘汰策略( LRU )就是在 LinkedHashMap 上扩展的。
数组在内存中如何分配
对于 Java 数组的初始化,有以下两种方式,这也是面试中经常考到的经典题目:
静态初始化:初始化时由程序员显式指定每个数组元素的初始值,由系统决定数组长度,如:
//只是指定初始值,并没有指定数组的长度,但是系统为自动决定该数组的长度为4
String[] computers = {"Dell", "Lenovo", "Apple", "Acer"}; //①
//只是指定初始值,并没有指定数组的长度,但是系统为自动决定该数组的长度为3
String[] names = new String[]{"多啦A梦", "大雄", "静香"}; //②
动态初始化:初始化时由程序员显示的指定数组的长度,由系统为数据每个元素分配初始值,如:
//只是指定了数组的长度,并没有显示的为数组指定初始值,但是系统会默认给数组数组元素分配初始值为null
String[] cars = new String[4];//③
因为 Java 数组变量是引用类型的变量,所以上述几行初始化语句执行后,三个数组在内存中的分配情况如下图所 示:
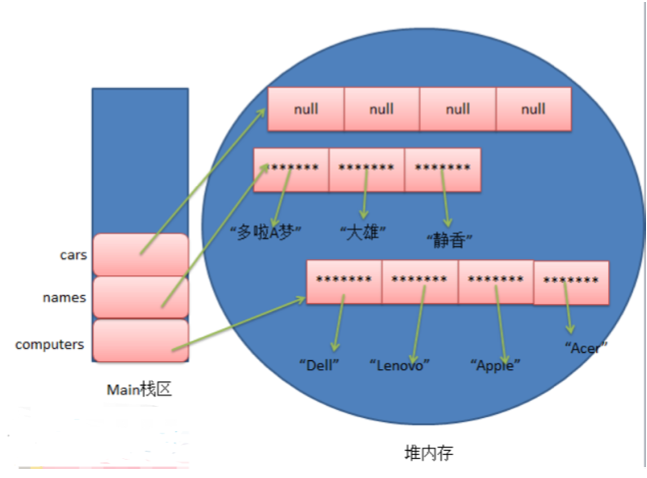
由上图可知,静态初始化方式,程序员虽然没有指定数组长度,但是系统已经自动帮我们给分配了,而动态初始化 方式,程序员虽然没有显示的指定初始化值,但是因为 Java 数组是引用类型的变量,所以系统也为每个元素分配 了初始化值 null ,当然不同类型的初始化值也是不一样的,假设是基本类型int类型,那么为系统分配的初始化值 也是对应的默认值0。
Spring知识导图笔记
怎么统计在线人员
转载:https://my.oschina.net/u/854926/blog/84375
我们给出的代码是使用session的监听器,因为我们知道一连接一个用户,就会产生一个新的session。而断开一个用户则会销毁一个session。我们分别在产生和销毁时对在线用户数加1或是-1。这样的数据与当前用户数大致相同。说大致相同是因为session的销毁要在用户退出后的一段时间。所以会造成一定的偏差。
public class OnlineCountListener implements HttpSessionListener {
private static int sessionCount = 0;
public void sessionCreated(HttpSessionEvent event) {
HttpSession session = event.getSession();
ServletContext application = session.getServletContext();
sessionCount++;
application.setAttribute(“onlineCount”, sessionCount);
}
public void sessionDestroyed(HttpSessionEvent event) {
HttpSession session = event.getSession();
ServletContext application = session.getServletContext();
if(sessionCount >= 1){
sessionCount = sessionCount – 1;
}
application.setAttribute(“onlineCount”, sessionCount);
}
}
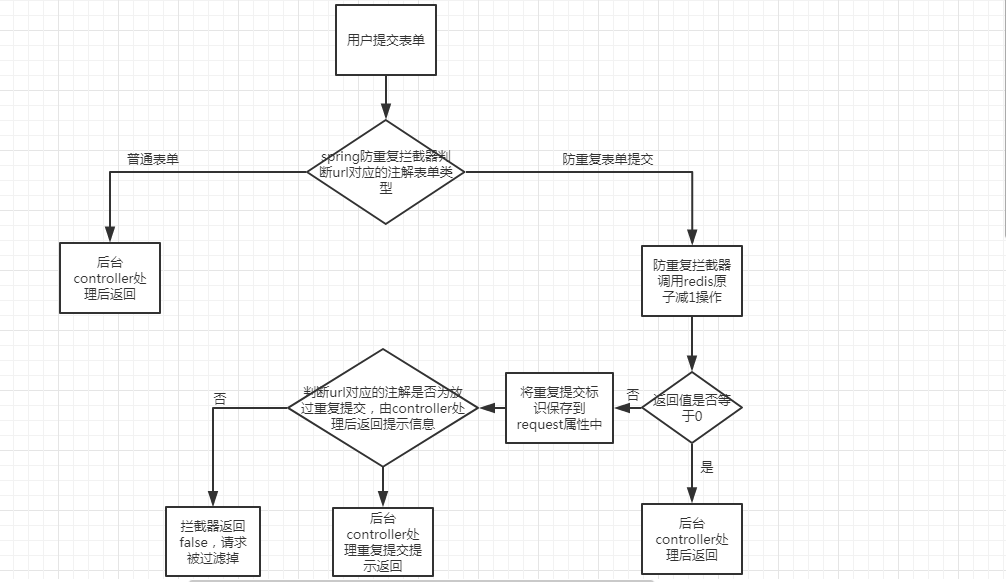
如何处理重复提交的问题
转载地址:https://my.oschina.net/u/2371923/blog/1921153
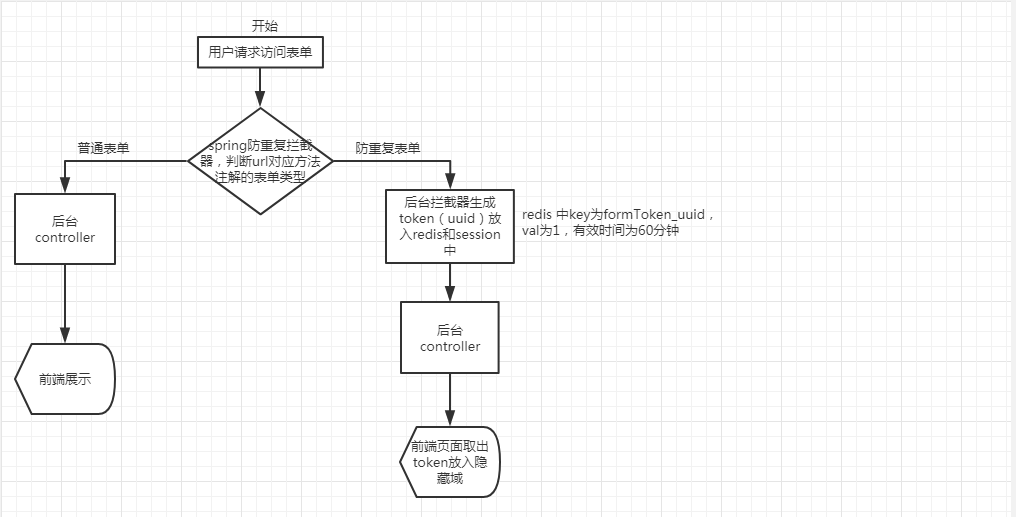
工作流程:
- 用户访问表单添加页面->spring防重复token拦截器拦截请求url,判断url对应的controller方法是是否注解有生成防重复token的标识也就是有没有这个注解标识->
- 生成防重复token保存到redis中RedisUtil.getRu().setex(“formToken_” + uuid, “1”, 60 * 60);同时将本次生成的防重复token放到session中->
- 转到表单页面时从session中取出token放入表单->
- 用户填写完信息提交表单->spring防重复token拦截器拦截请求url,判断提交的url对应controller方法是否注解有处理防重复提交token的标识->
- redis中formToken做原子减1操作RedisUtil.getRu().decr(“formToken_” + clinetToken);如果redis中formToken值做了减1操作后值不为0,则为重复提交,返回false。
防重复提交token生成流程图
防重复表单提交处理流程图
「真诚赞赏,手留余香」

真诚赞赏,手留余香
使用微信扫描二维码完成支付
